
 | Chapter 11 Implementing Object Persistence |  |
This section explains the implementation of Adaptor::DBI and Adaptor::File. We will cover only the key procedures that perform query processing and file or database I/O. Pay as much attention to the design gotchas and unimplemented features as you do to the code.
An Adaptor::File instance represents all objects stored in one file. When this adaptor is created (using new), it reads the entire file and translates the data to in-memory objects. Slurping the entire file into memory avoids the problem of having to implement fancy on-disk schemes for random access to variable-length data; after all, that is the job of DBM and database implementations. For this reason, this approach is not recommended for large numbers of objects (over 1,000, to pick a number).
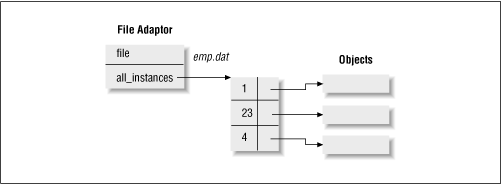
The file adaptor has an attribute called all_instances, a hash table of all objects given to its store method (and indexed by their _id), as shown in Figure 11.2.
Let us examine the two methods for storing objects to files: store() and flush.
store allocates a new unique identifier for the object (if necessary) and simply pegs the object onto the all_instances hash. It doesn't send the data to disk.
sub store { # adaptor->store($obj)
(@_ == 2) || die 'Usage adaptor->store ($obj_to_store)';
my ($this, $obj_to_store) = @_; # $this is 'all_instances'
my ($id) = $obj_to_store->get_attributes('_id');
my $all_instances = $this->{all_instances};
if (!defined ($id )) {
# Haven't seen this object before. Generate an id (doesn't
# matter how this id is generated)
$id = $this->_get_next_id();
$obj_to_store->set_attributes('_id'=> $id);
}
$all_instances->{$id} = $obj_to_store;
$id; # Return the object identifier
}Note that the object is told about its new identifier (using set_attributes), so if it is given again to store, a new identifier is not allocated.
The real work of storing the data in the file is done by flush:
sub flush { # adaptor->flush();
my $this = $_[0];
my $all_instances = $this->{'all_instances'};
my $file = $this->{'file'};
return unless defined $file;
open (F, ">$file") || die "Error opening $file: $!\n";
my ($id, $obj);
while (($id, $obj) = each %$all_instances) {
my $class = ref($obj);
my @attrs =
$obj->get_attributes(@{$this->get_attrs_for_class($class)});
Storable::store_fd([$class, $id, @attrs], \*F);
}
close(F);
}flush simply walks the all_instances hash and, for each user-defined object, calls its get_attributes method. get_attrs_for_class returns a list of persistent attributes for each class (as an array reference) and is loaded from the configuration file supplied to the adaptor's constructor.
The attribute values, together with the class and instance identifier, are packaged in an anonymous array before being given to Storable::store_fd.
This implementation is unsatisfactorily slow (a second or two to store 1,000 objects), largely because so many lookups and accessor functions are called per object. At this stage of prototyping, I do not consider it a big issue.
The load_all method, called from new, simply does the reverse of flush. It reads the file, recreates each object, and inserts it in the all_instances attribute as shown:
sub load_all { # $all_instances = load_all($file);
my $file = shift;
return undef unless -e $file;
open(F, $file) || croak "Unable to load $file: $!";
# Global information first
my ($class, $id, $obj, $rh_attr_names, @attrs, $all_instances);
eval {
while (1) {
($class, $id, @attrs) = @{Storable::retrieve_fd(\*F)};
$obj = $all_instances->{$id};
$obj = $class->new() unless defined($obj);
$rh_attr_names = $this->get_attrs_for_class($class);
$obj->set_attributes(
"_id" => $id,
map {$rh_attr_names->[$_] => $attrs[$_]}
(0 .. $#attrs)
);
$all_instances->{$id} = $obj;
}
};
$all_instances;
}load_all calls Storable's retrieve_fd function, calls the constructor of the appropriate class (new) to construct an uninitialized object of that class, and invokes set_attributes on this newly created object. The map statement constructs a list of attribute name-value pairs. When Storable::retrieve_fd has no more data, it throws an exception (using die). It breaks the infinite loop but is trapped by the eval.
The retrieve_where method accepts a class name and a query expression, which is a subset of the SQL syntax. The query is not guaranteed to work for SQL keywords such as LIKE, BETWEEN, and IN; however, it will work for the database adaptor because it is sent untranslated to the database.
Writing a query processor for parsing and executing arbitrary query expressions is not a trivial task. But we know that Perl itself deals with expression evaluation, so if we can convert a query to a Perl expression, we can simply use eval to do the dirty work for us, as we saw in Chapter 5, Eval.
retrieve_where hence invokes parse_query to convert the expression to an evalable Perl Boolean expression and dynamically creates a piece of code incorporating this expression to traverse all the objects in the all_instances attribute. That is, a call such as:
retrieve_where ('Employee', 'age < 45 && name != 'John')is translated to the following piece of Perl code, and evaled:
my $dummy_key; my $obj;
while (($dummy_key, $obj) = each %$all_instances) {
next unless ref($obj) eq "Employee";
my ($age, $name) = $obj->get_attributes(qw(age name));
push (@retval, $obj) if $age < 45 && $name ne 'John';
}The Boolean expression in the push statement and the list of attribute names are both returned by parse_query, discussed later. retrieve_where is implemented like this:
sub retrieve_where {
my ($this, $class, $query) = @_;
my $all_instances = $$this;
# blank queries result in a list of all objects
return $this->retrieve_all() if ($query !~ /\S/);
my ($boolean_expression, @attrs) = parse_query($query);
# @attrs contains the attribute names used in the query
# Construct a statement to fetch the required attributes,
# of the form:
# my ($name, $age) = $obj->get_attributes(qw(name age));
my $fetch_stmt = "my (" . join(",",map{'$' . $_} @attrs) . ") = " .
"\$obj->get_attributes(qw(@attrs))";
my (@retval);
my $eval_str = qq{
my \$dummy_key; my \$obj;
while ((\$dummy_key, \$obj) = each \%\$all_instances) {
next unless ref(\$obj) eq "$class";
$fetch_stmt;
push (\@retval, \$obj) if ($boolean_expression);
}
};
print STDERR "EVAL:\n\t$eval_str\n" if $debugging ;
eval ($eval_str);
if ($@) {
print STDERR "Ill-formed query:\n\t$query\n";
print STDERR $@ if $debugging;
}
@retval;
}Instead of constructing a list of objects for every query, retrieve_where should optionally take a callback reference as the third parameter, which can be called for every object that matches this query.
Now let us take a look at parse_query, which, as was mentioned earlier, translates the SQL where clause to a Perl expression. The input query expression is essentially a series of query terms of the form variable op value, strung together with logical operators (&& and ||). The rules of the transformation are as follows:
Escaped quotes should be preserved. That is, a string such as "foo\'bar" should not cause confusion.
variable is mapped to $variable. When processing this step, parse_query also keeps a note of the attribute names encountered. This list is returned to its calling procedure, retrieve_where.
If value is a quoted string, then op gets mapped to the appropriate string comparison operator (see %string_op below).
parse_query is implemented like this:
my %string_op = ( # Map from any operator to corresponding string op
'==' => 'eq',
'<' => 'lt',
'<=' => 'le',
'>' => 'gt',
'>=' => 'ge',
'!=' => 'ne',
);
my $ANY_OP = '<=|>=|<|>|!=|=='; # Any comparison operator
sub parse_query {
my ($query) = @_;
# Rule 1.
return 1 if ($query =~ /^\s*$/);
# First squirrel away all instances of escaped quotes - Rule 2.
# This way it doesn't get in the way when we are processing
# rule 5.
$query =~ s/\\[# Hopefully \200 and \201 aren't being
$query =~ s/\\["]/\201/g; # being used.
# Rule 3 - Replace all '=' by '=='
$query =~ s/([^!><=])=/$1 == /g;
my %attrs;
# Rule 4 - extract fields, and replace var with $var
$query =~
s/(\w+)\s*($ANY_OP)/$attrs{$1}++, "\$$1 $2"/eg;
# Rule 5 - replace comparison operators before quoted strings
# with string comparison opersators
$query =~
s{
($ANY_OP) (?# Any comparison operator)
\s* (?# followed by zero or more spaces,)
[' (?# then by a quoted string )
}{
$string_op{$1} . ' \'' . $2 . '\''
}goxse; # global, compile-once, extended,
# treat as single line, eval
# Restore all escaped quote characters
$query =~ s/\200/\\'/g;
$query =~ s/\201/\\"/g;
($query, keys %attrs); # Return modified query, and field list
}Adaptor::DBI is considerably simpler than Adaptor::File. It does not maintain a table of objects in memory; when asked to store an object, it sends it to the database, and when asked to retrieve one or more objects, it simply passes the request along to the database. This scheme is also its biggest failing, as was pointed out earlier in the section "Uniqueness of Objects in Memory."
The new method simply opens a DBI connection, as was illustrated in Chapter 10, Persistence, and creates an adaptor object with the connection handle as its sole attribute. No rocket science here.
The adaptor's store method sends an object to the database:
sub store { # adaptor->store($obj)
(@_ == 2) || croak 'Usage adaptor->store ($obj)';
my $sql_cmd;
my ($this, $obj) = @_;
my $class = ref($obj);
my $rh_class_info = $map_info{$class};
my $table = $rh_class_info->{"table"};
croak "No mapping defined for package $class"
unless defined($table);
my $rl_attr_names = $rh_class_info->{"attributes"};
my ($id) = $obj->get_attributes('_id');
my ($attr);
if (!defined ($id )) {
$id = $this->_get_next_id($table);
$obj->set_attributes('_id'=> $id);
# Generate a statement like:
# insert into Employee (_id, name, age)
# values (100, "jason", 33)
$sql_cmd = "insert into $table (";
my ($col_name, $type, $attr);
my (@attrs) = $obj->get_attributes(@$rl_attr_names);
$sql_cmd .= join(",",@$rl_attr_names) . ") values (";
my $val_cmd = "";
foreach $attr (@attrs) {
my $quote = ($attr =~ /\D/)
? "'"
: "";
$val_cmd .= "${quote}${attr}${quote},";
}
chop ($val_cmd);
$sql_cmd .= $val_cmd . ")" ;
} else {
# Object already exists in the database. Update it
# with a statement like:
# update Employee set name = "jason", age = 33
# where _id = 100;
$sql_cmd = "update $table set ";
my ($name, $quote);
my @attrs = $obj->get_attributes(@$rl_attr_names);
foreach $name (@$rl_attr_names) {
if ($name eq '_id') {
shift @attrs; # Can't update primary row
next;
}
$attr = shift @attrs;
$quote = ($attr =~ /\D/)
? "'"
: "";
$sql_cmd .= "$name=${quote}${attr}${quote},";
}
chop($sql_cmd); # remove trailing comma
$sql_cmd .= " where _id = $id";
}
# Sql query constructed. Give it to the appropriate db connection
# to execute.
$this->{dbconn}->do($sql_cmd); #
die "DBI Error: $DBI::errstr" if $DBI::err;
$id;
}The global variable %map_info stores database configuration information for every package mentioned in the configuration file: the name of the corresponding database table, the list of persistent attributes, and the corresponding database column names. If the object already has an attribute called _id , the corresponding database row is updated; otherwise, a new identifier is allocated and a new database row is inserted. All string valued attributes are automatically quoted.
Clearly, we can do much better than this implementation. If we create 1000 objects, the preceding code creates and evaluates 1000 fresh SQL insert statements. A better approach is to prepare insert/delete/update/fetch statements for each class the first time an object of that class is encountered, like this:
$insert{'Employee'} = $dbh->prepare (
"insert into Employee (_id, name, age)
values (? , ? , ? )");
$delete{'Employee'} = $dbh->prepare (
"delete from Employee where _id = ?";
$update{'Employee'} = $dbh->prepare (
"update Employee (name=?, age=?");
$fetch {'Employee'} = $dbh->prepare (
"select name, age, from Employee
where _id = ?");store can simply execute these statements with the appropriate statements. An even faster way is to take advantage of stored procedures. As it stands, the current implementation works reasonably well for prototypes.
Incidentally, Adaptor::DBI's flush() method does not do anything, because store() doesn't keep any object in memory.
retrieve_where creates a select query from the mapping information for that class. As was pointed out earlier, the same query executed twice will get you two different sets of objects, whose data are duplicates of the other:
sub retrieve_where {
my ($this, $class, $query) = @_;
my $where;
$where = ($query =~ /\S/)
? "where $query"
: "";
my $rh_class_info = $map_info{$class};
my $table = $rh_class_info->{"table"};
croak "No mapping defined for package $class"
unless defined($table);
my $rl_attr_names = $rh_class_info->{"attributes"};
my $rl_col_names = $rh_class_info->{"columns"};
my $sql_cmd = "select "
. join(",", @{$rl_col_names})
. " from $table $where";
print $sql_cmd if $debugging;
my $rl_rows = $this->{d}->do($sql_cmd);
my @retval;
my $size = @$rl_attr_names - 1;
if ($rl_rows && @$rl_rows) {
my $i; my $rl_row;
foreach $rl_row (@$rl_rows) {
my $obj = $class->new;
$obj->set_attributes(map {
$rl_attr_names->[$_] => $rl_row->[$_]
}(0 .. $size));
push (@retval, $obj);
}
}
@retval;
}The preceding set_attributes statement perhaps requires some explanation. The objective of this statement is to set all the attributes returned by the database. Since set_attributes requires a list of name-value pairs, we use the map built-in function to return a list. This function takes two parameters - a block of code and a list - and, for each element of the list, evaluates the block in a list context. The function returns a list containing the result executing that block across all iterations.
At this point, if your enthusiasm continues unabated, you may find it worthwhile to go back and understand how Adaptor handles the issues raised in the "Design Notes" section.
|  | |
| 11.2 Design Notes |  | 11.4 Resources |