
 | Chapter 2 Executing Dynamic SQL and PL/SQL |  |
DBMS_SQL is an extremely powerful package, but it is also one of the most complicated built-in packages to use. Sure, you can construct and execute any SQL statement you desire. The trade-off for that flexibility is that you have to do lots more work to get your SQL-related job done. You must specify all aspects of the SQL statement, usually with a wide variety of procedure calls, from the SQL statement itself down to the values of bind variables and the datatypes of columns in SELECT statements. Before I explore each of the programs that implement these steps, let's review the general flow of events that must occur in order to use DBMS_SQL successfully.
In order to execute dynamic SQL with DBMS_SQL you must follow these steps; see Figure 2.1 for a graphical summary:
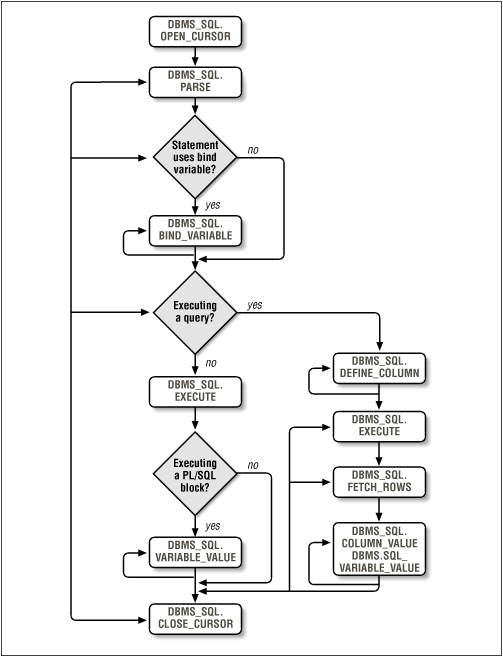
Open a cursor. When you open a cursor, you ask the RDBMS to set aside and maintain a valid cursor structure for your use with future DBMS_SQL calls. The RDBMS returns an INTEGER handle to this cursor. You will use this handle in all future calls to DBMS_SQL programs for this dynamic SQL statement. Note that this cursor is completely distinct from normal, native PL/SQL cursors.
Parse the SQL statement. Before you can specify bind variable values and column structures for the SQL statement, it must be parsed by the RDBMS. This parse phase verifies that the SQL statement is properly constructed. It then associates the SQL statement with your cursor handle. Note that when you parse a DDL statement, it is also executed immediately. Upon successful completion of the DDL parse, the RDBMS also issues an implicit commit. This behavior is consistent with that of SQL*Plus.
Bind all host variables. If the SQL statement contains references to host PL/SQL variables, you will include placeholders to those variables in the SQL statement by prefacing their names with a colon, as in :salary. You must then bind the actual value for that variable into the SQL statement.
Define the columns in SELECT statements. Each column in the list of the SELECT must be defined. This define phase sets up a correspondence between the expressions in the list of the SQL statement and the local PL/SQL variables receiving the values when a row is fetched (see COLUMN_VALUE). This step is only necessary for SELECT statements and is roughly equivalent to the INTO clause of an implicit SELECT statement in PL/SQL.
Execute the SQL statement. Execute the specified cursor -- that is, its associated SQL statement. If the SQL statement is an INSERT, UPDATE, or DELETE, the EXECUTE command returns the numbers of rows processed. Otherwise, you should ignore that return value.
Fetch rows from the dynamic SQL query. If you execute a SQL statement, you must then fetch the rows from the cursor, as you would with a normal PL/SQL cursor. When you fetch, however, you do not fetch directly into local PL/SQL variables.
Retrieve values from the execution of the dynamic SQL. If the SQL statement is a query, retrieve values from the SELECT expression list using COLUMN_VALUE. If you have passed a PL/SQL block containing calls to stored procedures, use VARIABLE_VALUE to retrieve the values returned by those procedures.
Close the cursor. As with normal PL/SQL cursors, always clean up by closing the cursor when you are done. This releases the memory associated with the cursor.
Before you perform any kind of dynamic SQL, you must obtain a pointer to memory in which the dynamic SQL will be managed. You do this by "opening the cursor," at which point Oracle sets aside memory for a cursor data area and then returns a pointer to that area.
These pointers are different from the cursors defined by other elements of Oracle, such as the Oracle Call Interface (OCI) and precompiler interfaces and even PL/SQL's static cursors.
Use this function to open a cursor. Here's the specification:
FUNCTION DBMS_SQL.OPEN_CURSOR RETURN INTEGER;
Notice that you do not provide a name for the cursor. You are simply requesting space in shared memory for the SQL statement and the data affected by that statement.
You can use a cursor to execute the same or different SQL statements more than once. When you reuse a cursor, the contents of the cursor data area are reset if a new SQL statement is parsed. You do not have to close and reopen a cursor before you reuse it. You absolutely do not have to open a new cursor for each new dynamic SQL statement you want to process. When you are done with the cursor, you should remove it from memory with a call to the CLOSE_CURSOR procedure.
The following example demonstrates the use of a single cursor for two different SQL statements. I declare a cursor, use it to create an index, and then use it to update rows in the emp table.
CREATE OR REPLACE PROCEDURE do_two_unrelated_actions
(tab_in IN VARCHAR2, col_in IN VARCHAR2, val_in IN NUMBER)
IS
cur BINARY_INTEGER := DBMS_SQL.OPEN_CURSOR;
fdbk BINARY_INTEGER;
BEGIN
/* Piece together a CREATE INDEX statement. */
DBMS_SQL.PARSE (cur,
'CREATE INDEX ind_' || tab_in || '$' || col_in || ' ON ' ||
tab_in || '(' || col_in || ')',
DBMS_SQL.NATIVE);
fdbk := DBMS_SQL.EXECUTE (cur);
/* Use the same cursor to do the update. */
DBMS_SQL.PARSE (cur,
'UPDATE ' || tab_in || ' SET ' || col_in || ' = :newval',
DBMS_SQL.NATIVE);
DBMS_SQL.BIND_VARIABLE (cur, 'newval', val_in);
fdbk := DBMS_SQL.EXECUTE (cur);
/* Free up the memory from the cursor. */
DBMS_SQL.CLOSE_CURSOR (cur);
END;
/The IS_OPEN function returns TRUE if the specified cursor is already open, and FALSE if the cursor has been closed or if the value does not point to a dynamic cursor,
FUNCTION DBMS_SQL.IS_OPEN (c IN INTEGER) RETURN BOOLEAN;
where c is the pointer to the cursor. This function corresponds to the %ISOPEN attribute for regular PL/SQL cursors.
Once you have allocated a pointer to a cursor, you can then associate that pointer with a SQL statement. You do this by parsing the SQL statement with a call to the PARSE procedure. The parse phase checks the statement's syntax, so if there is a syntax error, the call to PARSE will fail and an exception will be raised.
The PARSE procedure immediately parses the statement specified. It comes in two formats. The first, as follows, will be used in almost every case. For very large SQL statments, use the PL/SQL table-based version described in the next section.
PROCEDURE DBMS_SQL.PARSE
(c IN INTEGER,
statement IN VARCHAR2,
language_flag IN INTEGER);The parameters for this procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | The pointer to the cursor or memory area for this SQL statement. |
statement | The SQL statement to be parsed and associated with the cursor. This statement should not be terminated with a semicolon unless it is a PL/SQL block. |
language_flag | A flag determing how Oracle will handle the statement. Valid options are DBMS_SQL.V6, DBMS_SQL.V7, and DBMS_SQL.NATIVE. Use DBMS_SQL.NATIVE unless otherwise instructed by your DBA. |
Note that you cannot defer the parsing of this statement, as is possible with OCI. Statements in DBMS_SQL are parsed immediately. Oracle documentation does mention that this "may change in future versions; you should not rely on this behavior." This means that at some point in the future, Oracle Corporation may allow parsing to be deferred to the execute phase, thereby reducing network traffic. If this change occurs, let's hope that a flag is offered to preserve earlier functionality.
NOTE: The common understanding among long-time Oracle programmers is that when you parse DDL, it always executes, so a call to the EXECUTE procedure is not necessary when calling DBMS_SQL.PARSE for a DDL statement. You should not take this shortcut! Oracle will not guarantee that this behavior will continue in future releases. If you want to make sure that your DDL has executed, call the DBMS_SQL.EXECUTE procedure.
PL/SQL8 offers a second, overloaded version of PARSE, which comes in handy when you have very large SQL statements. If your SQL statement exceeds the largest possible contiguous allocation on your system (and it is machine-dependent) or 32Kbytes (the maximum size for VARCHAR2), then use this version of the PARSE procedure:
PROCEDURE DBMS_SQL.PARSE
(c IN INTEGER,
statement IN DBMS_SQL.VARCHAR2S,
lb IN INTEGER,
ub IN INTEGER,
lfflg IN BOOLEAN,
language_flag IN INTEGER);The parameters for this procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | The pointer to the cursor or memory area for this SQL statement. |
statement | The SQL statement to be parsed and associated with the cursor. In this case, you will be passing a PL/SQL table of the DBMS_SQL.VARCHAR2S type. |
lb | The lower bound or first row in the statement table to be parsed. |
ub | The upper bound or last row in the statement table to be parsed. |
lfflg | If TRUE, then a line-feed should be concatenated after each row in the table. |
language_flag | A flag determining how Oracle will handle the statement. Valid options are DBMS_SQL.V6, DBMS_SQL.V7, and DBMS_SQL.NATIVE. Use DBMS_SQL.NATIVE unless otherwise instructed by your DBA. |
My own parse_long_one procedure offers an example of using the array-based version of the PARSE procedure:
/* Filename on companion disk: parslong.sp */ CREATE OR REPLACE PROCEDURE parse_long_one (select_list IN VARCHAR2, from_list IN VARCHAR2, where_clause IN VARCHAR2, maxlen IN BINARY_INTEGER := 256, /* Can change the max. */ dbg IN BOOLEAN := FALSE /* Built-in debugging toggle */ ) IS /* Open the cursor as I declare the variable */ cur BINARY_INTEGER := DBMS_SQL.OPEN_CURSOR; /* Declare the index-by table based on the DBMS_SQL TYPE. */ sql_table DBMS_SQL.VARCHAR2S; /* Local module to extract up to the next maxlen chars. */ FUNCTION next_row (string_in IN VARCHAR2, start_inout IN OUT BINARY_INTEGER, len_in IN BINARY_INTEGER) RETURN VARCHAR2 IS v_start BINARY_INTEGER := start_inout; BEGIN start_inout := LEAST (len_in + 1, start_inout + maxlen); RETURN SUBSTR (string_in, v_start, maxlen); END; /* Local module to transfer string to index-by table. */ PROCEDURE fill_sql_table (string_in IN VARCHAR2) IS v_length BINARY_INTEGER; v_start BINARY_INTEGER := 1; BEGIN IF string_in IS NOT NULL THEN v_length := LENGTH (string_in); LOOP sql_table (NVL (sql_table.LAST, 0)+1) := next_row (string_in, v_start, v_length); EXIT WHEN v_start > v_length; END LOOP; END IF; END; BEGIN /* Move each portion of the SELECT string to the table. */ fill_sql_table (select_list); fill_sql_table (from_list); fill_sql_table (where_clause); /* Parse everything from first to last row of table. */ DBMS_SQL.PARSE (cur, sql_table, sql_table.FIRST, sql_table.LAST, FALSE, DBMS_SQL.NATIVE); /* Execute and fetch rows if doing something for real... */ /* If debugging, then display contents of the table. */ IF dbg THEN DBMS_OUTPUT.PUT_LINE ('Parsed into lines of length ' || TO_CHAR (maxlen)); FOR rowind IN sql_table.FIRST .. sql_table.LAST LOOP DBMS_OUTPUT.PUT_LINE (sql_table(rowind)); END LOOP; END IF; /* Close the cursor when done. */ DBMS_SQL.CLOSE_CURSOR (cur); END; /
Here is a little test script (and the results of execution) for this procedure:
SQL> BEGIN
parse_long_one ('select empno, ename, sal, hiredate, mgr, comm ',
'from emp ', 'where empno = empno and sal = sal', 10, TRUE);
END;
/
Parsed into lines of length 10
select emp
no, ename,
sal, hire
date, mgr,
comm
from emp
where empn
o = empno
and sal =
sal
/ Notice that the SELECT statement is broken without any concern for keeping identifiers intact. The lfflg value passed in to the PARSE procedure is set to FALSE so linefeeds are not concatenated. As a result, the broken identifiers are concatenated back together and the SQL statement parses without any difficulty.
The SQL (or PL/SQL) statement you execute is constructed as a string at runtime. In most scenarios, you are using dynamic SQL because all the information about the SQL statement is not known at compile time. You therefore have values that you want to pass into the SQL statement at runtime. You have two ways of doing this: concatenation and binding. With concatenation, you convert all elements of the SQL statement into strings and concatenate them together. With binding, you insert placeholders in your string (identifiers prefaced with a colon) and then explicitly bind or associate a value with that placeholder before executing the SQL statement.
If you concatenate the value into the string, then you are not really binding values and you do not have to make calls to the BIND_VARIABLE or BIND_ARRAY procedures. Here is an example of the parsing of a dynamically constructed string relying on concatenation:
DBMS_SQL.PARSE (cur, 'SELECT * FROM emp WHERE ename LIKE ' || v_ename);
At runtime the string is cobbled together and passed to the SQL engine for parsing. With binding, you would write code like this:
DBMS_SQL.PARSE (cur, 'SELECT * FROM emp WHERE ename LIKE :varname'); DBMS_SQL.BIND_VARIABLE (cur, 'varname', var_name_in);
Binding involves writing more code, but offers much more flexibility and power. The following comparison between concatenation and binding techniques will help you decide which to use:
When you concatenate, you convert to a string format. This can become awkward and error-prone. With binding, you do not perform any conversions. Instead, the native datatypes are employed.
When you execute DDL statements dynamically, you cannot use bind variables. Your only choice is to concatenate together the strings and then pass that to the engine. This makes sense, since, at least in the current version of DBMS_SQL, there is no such thing as deferred parsing. When you parse, you also execute DDL.
You can execute the same dynamic cursor more than once, and each time you bind in different values to the SQL statement. This is not possible if you concatenate the values into the string at the time of parsing.
With bind variables, you can take advantage of the new array-processing features of PL/SQL8's DBMS_SQL package. You can bind an entire array of scalar values into the SQL string and then apply each of those values in a single SQL execution.
So if you decide that you really do want to bind variables into your dynamic SQL, use one of the programs described in the following sections.
The BIND_VARIABLE procedure binds a scalar value to a placeholder in your SQL statement. A placeholder is an identifier prefaced by a colon, as in :myval. Call BIND_VARIABLE after DBMS_SQL.PARSE, but before calls to EXECUTE and EXECUTE_AND_FETCH. This procedure is overloaded to allow you to bind a number of different types of data. This is the header:
PROCEDURE DBMS_SQL.BIND_VARIABLE
(c IN INTEGER,
name IN VARCHAR2,
value IN <datatype>);The parameters for this procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | The handle or pointer to the cursor originally returned by a call to OPEN_CURSOR. |
name | The name of the placeholder included in the SQL statement passed to PARSE. |
value | The value to be bound to the placeholder variable. |
<datatype> may be any of the following:
BFILE BLOB CLOB CHARACTER SET ANY_CS DATE MLSLABEL /*Trusted Oracle only*/ NUMBER VARCHAR2 CHARACTER SET ANY_CS_ARRAY
Here is an example of binding the current date/time into a placeholder called "now:"
DBMS_SQL.BIND_VARIABLE (cur, 'now', SYSDATE);
Here is an example of binding the literal value "Liberation Theology" into a placeholder called "progress:"
DBMS_SQL.BIND_VARIABLE (cur, ':progress', 'Liberation Theology');
Notice that you can include or leave out the colon when you specify the placeholder name.
The DBMS_SQL package also offers more specific variants of BIND_VARIABLE for less-common datatypes,
PROCEDURE DBMS_SQL.BIND_VARIABLE
(c IN INTEGER,
name IN VARCHAR2,
value IN VARCHAR2 CHARACTER SET ANY_CS,
[,out_value_size IN INTEGER]);
PROCEDURE DBMS_SQL.BIND_VARIABLE_CHAR
(c IN INTEGER,
name IN VARCHAR2,
value IN CHAR CHARACTER SET ANY_CS,
[,out_value_size IN INTEGER]);
PROCEDURE DBMS_SQL.BIND_VARIABLE_RAW
(c IN INTEGER,
name IN VARCHAR2,
value IN RAW
[,out_value_size IN INTEGER]);
PROCEDURE DBMS_SQL.BIND_VARIABLE_ROWID
(c IN INTEGER,
name IN VARCHAR2,
value IN ROWID);where out_value_size is the maximum size expected for the value that might be passed to this variable. Square brackets indicate optional parameters. If you do not provide a value for out_value_size, the size is the length of the current value provided.
For every placeholder you put in your SQL string, you must make a call to BIND_VARIABLE (or BIND_ARRAY). For example, the SELECT statement in the call to PARSE below contains two bind variables, :call_date and :call_type:
DBMS_SQL.PARSE
(the_cursor,
'SELECT COUNT(*) freq FROM call WHERE call_date = :call_date ' ||
'AND call_type_cd = :call_type',
DBMS_SQL.V7);I will therefore need to issue the following two calls to BIND_VARIABLE before I can execute the query,
DBMS_SQL.BIND_VARIABLE (the_cursor, 'call_date', :call.last_date_called); DBMS_SQL.BIND_VARIABLE (the_cursor, 'call_type', :call.call_status);
where the two bind values are items in an Oracle Forms screen. Since BIND_VARIABLE is overloaded, I can call it with either a date value or a string, and PL/SQL will execute the appropriate code. Notice that the name of the bind variable does not have to match any particular column name in the SELECT statement, and it does not have to match the name of the PL/SQL variable that may hold the value. The name is really just a placeholder into which a value is substituted.
You can also include the colon in the placeholder name when you bind the value to the variable:
DBMS_SQL.BIND_VARIABLE (the_cursor, ':call_date', :call.last_date_called);
If you want to avoid having to make these separate calls to BIND_VARIABLE, you can substitute these values into the SQL statement yourself at the time the statement is parsed. The code shows the same SELECT statement, but without any bind variables.
DBMS_SQL.PARSE
(the_cursor,
'SELECT COUNT(*) freq FROM call WHERE call_date = ''' ||
TO_CHAR (:call.last_date_called) ||
''' AND call_type_cd = ''' || :call.call_status || '''',
DBMS_SQL.V7);Kind of ugly, isn't it? All of those single quotes glommed together (three consecutive single quotes at the end of a string result in one single quote around the literal values stuffed into the SQL statement), the concatenation, datatype conversions, etc. This is the tradeoff for not using the programmatic interface provided by DBMS_SQL.
You will also call BIND_VARIABLE for every placeholder in a dynamic PL/SQL block, even if the placeholder is an OUT argument or is otherwise simply receiving a value. Consider the following PL/SQL procedure, which performs an assignment dynamically when it could simply do it explicitly:
CREATE OR REPLACE PROCEDURE assign_value (newval_in IN NUMBER)
IS
cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR;
fdbk PLS_INTEGER;
local_var NUMBER; /* Receives the new value */
BEGIN
DBMS_SQL.PARSE
(cur, 'BEGIN :container := :newval; END;', DBMS_SQL.NATIVE);
DBMS_SQL.BIND_VARIABLE (cur, 'newval', newval_in);
DBMS_SQL.BIND_VARIABLE (cur, 'container', 1);
fdbk := DBMS_SQL.EXECUTE (cur);
DBMS_SQL.VARIABLE_VALUE (cur, 'container', local_var);
END;
/Notice that even though the container placeholder's value before execution is irrelevant, I still needed to bind that placeholder to a value for the PL/SQL block to execute successfully.
With PL/SQL8, you can use the new BIND_ARRAY procedure to perform bulk selects, inserts, updates, and deletes to improve the performance of your application. This same procedure will allow you to use and manipulate index-by tables (previously known as PL/SQL tables) within dynamically constructed PL/SQL blocks of code. To perform bulk or array processing, you will associate one or more index-by tables with columns or placeholders in your cursor.
The BIND_ARRAY procedure establishes this association for you. Call this procedure after PARSE, but before calls to EXECUTE and EXECUTE_AND_FETCH:
PROCEDURE DBMS_SQL.BIND_ARRAY (c IN INTEGER, name IN VARCHAR2, <table_variable> IN <datatype>, [,index1 IN INTEGER, ,index2 IN INTEGER)]);
The parameters for this procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | The handle or pointer to the cursor originally returned by a call to OPEN_CURSOR. |
name | The name of the host variable included in the SQL statement passed to PARSE. |
index1 | The lower bound or row in the index-by table <table_variable> for the first table element. |
variable | See the following description. |
index2 | The upper bound or row in the index-by table <table_variable> for the last table element. |
The <table_variable> IN <datatype> clause may be any of the following:
n_tab IN DBMS_SQL.NUMBER_TABLE c_tab IN DBMS_SQL.VARCHAR2_TABLE d_tab IN DBMS_SQL.DATE_TABLE bl_tab IN DBMS_SQL.BLOB_TABLE cl_tab IN DBMS_SQL.CLOB_TABLE bl_tab IN DBMS_SQL.BFILE_TABLE
The following example shows how I can use BIND_ARRAY to update multiple numeric rows of any table that has a numeric primary key:
/* Filename on companion disk: updarray.sp */ CREATE OR REPLACE PROCEDURE updarray (tab IN VARCHAR2, keycol IN VARCHAR2, valcol IN VARCHAR2, keylist IN DBMS_SQL.NUMBER_TABLE, vallist IN DBMS_SQL.NUMBER_TABLE) IS cur INTEGER := DBMS_SQL.OPEN_CURSOR; fdbk INTEGER; mytab DBMS_SQL.NUMBER_TABLE; BEGIN DBMS_SQL.PARSE (cur, 'UPDATE ' || tab || ' SET ' || valcol || ' = :vals ' || ' WHERE ' || keycol || ' = :keys', DBMS_SQL.NATIVE); DBMS_SQL.BIND_ARRAY (cur, 'keys', keylist); DBMS_SQL.BIND_ARRAY (cur, 'vals', vallist); fdbk := DBMS_SQL.EXECUTE (cur); DBMS_SQL.CLOSE_CURSOR (cur); END; /
Now I can execute this "update by array" procedure for the sal column of the emp table.
DECLARE
emps DBMS_SQL.NUMBER_TABLE;
sals DBMS_SQL.NUMBER_TABLE;
BEGIN
emps (1) := 7499;
sals (1) := 2000;
emps (2) := 7521;
sals (2) := 3000;
updarray ('emp', 'empno', 'sal', emps, sals);
END;
/The section on the DEFINE_ARRAY procedure and the section called "Array Processing with DBMS_SQL" provide additional examples of using BIND_ARRAY.
There are a number of factors to keep in mind when you are binding with index-by tables.
At the time of binding, the contents of the nested table are copied from your private global area to the DBMS_SQL buffers. Consequently, if you make changes to the nested table after your call to DBMS_SQL.BIND_ARRAY, those changes will not affect the cursor when executed.
If you specify values for index1 and/or index2, then those rows must be defined in the nested table. The value of index1 must be less than or equal to index2. All elements between and included in those rows will be used in the bind, but the table does not have to be densely filled.
If you do not specify values for index1 and index2, the first and last rows defined in the nested table will be used to set the boundaries for the bind.
Suppose that you have more than one bind array in your statement and the bind ranges (or the defined rows, if you did not specify) for the arrays are different. DBMS_SQL will then use the smallest common range -- that is, the greatest of the lower bounds and the least of the upper bounds.
You can mix array and scalar binds in your dynamic SQL execution. If you have a scalar bind, the same value will be used for each element of the arrays.
When fetching data using dynamic SQL, you cannot use arrays in both the bind and define phases. You may not, in other words, specify multiple bind values and at the same time fetch multiple rows into an array.
The OPEN_CURSOR procedure allocates memory for a cursor and its result set and returns a pointer to that area in memory. It does not, however, give any structure to that cursor. And even after you parse a SQL statement for that pointer, the cursor itself still does not have any internal structure. If you are going to execute a SELECT statement dynamically and extract values of columns in retrieved rows, you will need to take the additional step of defining the datatype of the individual columns in the cursor.
Each cursor column is, essentially, a container which will hold fetched data. You can use the DEFINE_COLUMN procedure to define a "scalar" column -- one that will hold a single value. You can also (with PL/SQL8) call DEFINE_ARRAY to create a column that will hold multiple values, allowing you to fetch rows in bulk from the database.
When you call the PARSE procedure to process a SELECT statement, you need to pass values from the database into local variables. To do this, you must tell DBMS_SQL the datatypes of the different columns or expressions in the SELECT list by making a call to the DEFINE_COLUMN procedure:
PROCEDURE DBMS_SQL.DEFINE_COLUMN
(c IN INTEGER,
position IN INTEGER,
column IN <datatype>);The parameters for this procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | Pointer to the cursor. |
position | The relative position of the column in the SELECT list. |
column | A PL/SQL variable or expression whose datatype determines the datatype of the column being defined. The particular value being passed in is irrelevant. |
<datatype> may be one of the following data types: NUMBER, DATE, MLSLABEL, BLOB, CLOB CHARACTER SET ANY_CS, BFILE
The DBMS_SQL package also offers more specific variants of DEFINE_COLUMN for less-common datatypes.
PROCEDURE DBMS_SQL.DEFINE_COLUMN
(c IN INTEGER
,position IN INTEGER
,column IN VARCHAR2 CHARACTER SET ANY_CS
,column_size IN INTEGER);
PROCEDURE DBMS_SQL.DEFINE_COLUMN_CHAR
(c IN INTEGER
,position IN INTEGER
,column IN CHAR CHARACTER SET ANY_CS
,column_size IN INTEGER);
PROCEDURE DBMS_SQL.DEFINE_COLUMN_RAW
(c IN INTEGER
,position IN INTEGER
,column IN RAW
,column_size IN INTEGER);
PROCEDURE DBMS_SQL.DEFINE_COLUMN_ROWID
(c IN INTEGER
,position IN INTEGER
,column IN ROWID);
PROCEDURE DBMS_SQL.DEFINE_COLUMN_LONG
(c IN INTEGER
,position IN INTEGER);You call DEFINE_COLUMN after the call to the PARSE procedure, but before the call to EXECUTE or EXECUTE_AND_FETCH. Once you have executed the SELECT statement, you will then use the COLUMN_VALUE procedure to grab a column value from the select list and pass it into the appropriate local variable.
The following code shows the different steps required to set up a SELECT statement for execution with DBMS_SQL:
DECLARE
/* Declare cursor handle and assign it a pointer */
c INTEGER := DBMS_SQL.OPEN_CURSOR;
/* Use a record to declare local structures. */
rec employee%ROWTYPE;
/* return value from EXECUTE; ignore in case of query */
execute_feedback INTEGER;
BEGIN
/* Parse the query with two columns in SELECT list */
DBMS_SQL.PARSE
(c,
'SELECT employee_id, last_name FROM employee',
DBMS_SQL.V7);
/* Define the columns in the cursor for this query */
DBMS_SQL.DEFINE_COLUMN (c, 1, rec.empno);
DBMS_SQL.DEFINE_COLUMN (c, 2, rec.ename, 30);
/* Now I can execute the query */
execute_feedback := DBMS_SQL.EXECUTE (c);
...
DBMS_SQL.CLOSE_CURSOR (c)
END;Notice that with the DEFINE_COLUMN procedure, you define columns (their datatypes) using a sequential position. With BIND_VARIABLE, on the other hand, you associate values to placeholders by name.
If you are working with PL/SQL8, you have the option of defining a column in the cursor which is capable of holding the values of multiple fetched rows. You accomplish this with a call to the DEFINE_ARRAY procedure:
PROCEDURE DBMS_SQL.DEFINE_ARRAY
(c IN INTEGER
,position IN INTEGER
,<table_parameter> IN <table_type>
,cnt IN INTEGER
,lower_bound IN INTEGER);The DEFINE_ARRAY parameters are summarized in the following table.
Parameter | Description |
|---|---|
c | Pointer to cursor. |
position | The relative position of the column in the select list. |
<table_parameter> | The nested table which is used to tell DBMS_SQL the datatype of the column. |
cnt | The maximum number of rows to be fetched in the call to the FETCH_ROWS or EXECUTE_AND_FETCH functions. |
lower_bound | The starting row (lower bound) in which column values will be placed in the nested table you provide in the corresponding call to the COLUMN_VALUE or VARIABLE_VALUE procedures. |
<table_parameter> IN <table_type> is one of the following:
n_tab IN DBMS_SQL.NUMBER_TABLE c_tab IN DBMS_SQL.VARCHAR2_TABLE d_tab IN DBMS_SQL.DATE_TABLE bl_tab IN DBMS_SQL.BLOB_TABLE cl_tab IN DBMS_SQL._TABLE bf_tab IN DBMS_SQL.BFILE_TABLE
When you call the COLUMN_VALUE or VARIABLE_VALUE procedures against an array-defined column, the Nth fetched column value will be placed in the lower_bound+N-1th row in the nested table. In other words, if you have fetched three rows and your call to DEFINE_ARRAY looked like this:
DECLARE datetab DBMS_SQL.DATE_TABLE; BEGIN DBMS_SQL.DEFINE_ARRAY (cur, 2, datetab, 10, 15); ...execute and fetch rows... DBMS_SQL.COLUMN_VALUE (cur, 2, datetab); END;
then the data will be placed in datetab(15), datetab(16), and datetab(17).
So you've opened and parsed the cursor. You've bound your variables and defined your columns. Now it's time to get some work done.
The EXECUTE function executes the SQL statement associated with the specified cursor,
FUNCTION DBMS_SQL.EXECUTE (c IN INTEGER) RETURN INTEGER;
where c is the pointer to the cursor. This function returns the number of rows processed by the SQL statement if that statement is an UPDATE, INSERT, or DELETE. For all other SQL (queries and DDL) and PL/SQL statements, the value returned by EXECUTE is undefined and should be ignored.
If the SQL statement is a query, you can now call the FETCH_ROWS function to fetch rows that are retrieved by that query. If you are executing a query, you can also use EXECUTE_AND_FETCH to execute the cursor and fetch one or more rows with a single program call.
You can fetch one or more rows of data from a dynamically constructed query with either the FETCH_ROWS or EXECUTE_AND_FETCH functions.
NOTE: Prior to PL/SQL8, both of these functions would return either 0 (no rows fetched) or 1 (one row fetched). With PL/SQL8 and array processing, these functions will return 0 (no rows fetched) or the actual number of rows fetched.
The FETCH_ROWS function corresponds to the FETCH statement for regular PL/SQL cursors. It fetches the next N rows from the cursor (a maximum of one if not using array processing in PL/SQL8). Here's the specification for the function,
FUNCTION DBMS_SQL.FETCH_ROWS (c IN INTEGER) RETURN INTEGER;
where c is the pointer to the cursor. The function returns 0 when there are no more rows to fetch. You can therefore use FETCH_ROWS much as you would FETCH and the %FOUND (or %NOTFOUND) attributes. The following two sets of statements are equivalent:
Use a normal, static cursor:
FETCH emp_cur INTO emp_rec;
IF emp_cur%FOUND
THEN
... process data ...
END IF;Use DBMS_SQL to fetch rows:
IF DBMS_SQL.FETCH_ROWS (c) > 0
THEN
... process data ...
END IF;So that happens when you fetch past the end of the cursor's result set? With static cursors, you can fetch all you want and never raise an error. In the following block, for example, I fetch 1000 times from a table with 14 rows. (C'mon, you knew that, right? The emp table has 14 rows.)
DECLARE
CURSOR empcur IS SELECT * FROM emp;
emprec empcur%ROWTYPE;
BEGIN
OPEN empcur;
FOR rowind IN 1 .. 1000
LOOP
FETCH empcur INTO emprec;
END LOOP;
END;
/No problem -- and no exceptions! After the fourteenth fetch, the FETCH statement simply does nothing (and the record continues to hold the fourteenth row's information).
However, the "fetch past last record" behavior with dynamic SQL is different. The FETCH_ROWS function will raise the ORA-01002 exception: fetch out of sequence, if you fetch again after a call to FETCH_ROWS has returned 0. The following anonymous block raises the ORA-01002 error, because there are only three employees in department 10:
DECLARE
cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR;
fdbk PLS_INTEGER;
BEGIN
DBMS_SQL.PARSE
(cur, 'SELECT * FROM emp WHERE deptno = 10', DBMS_SQL.NATIVE);
fdbk := DBMS_SQL.EXECUTE_CURSOR (cur);
FOR Nfetch IN 1 .. 5
LOOP
/* On fetch #5 this will raise ORA-01002 */
fdbk := DBMS_SQL.FETCH_ROWS (cur);
END LOOP;
DBMS_SQL.CLOSE_CURSOR (cur);
END;
/The following procedure shows how you can employ the FETCH_ROWS logic inside of a loop to fetch each of the rows from a cursor and place column values in an Oracle Forms block:
/* Filename on companion disk: fillblck.fp */ PROCEDURE fill_block (where_clause_in IN VARCHAR2) /* || Query data from table using a dynamic where clause and then || pass those values to an Oracle Forms block. */ IS /* || Declare cursor handle and parse the query, all in a single || statement using open_and_parse (see PARSE description). */ c INTEGER := DBMS_SQL.OPEN_CURSOR; emprec employee%ROWTYPE; /* return value from EXECUTE; ignore in case of query */ fdbk INTEGER; BEGIN /* Parse the query with a dynamic WHERE clause */ DBMS_SQL.PARSE (c, 'SELECT employee_id, last_name ' || ' FROM employee WHERE ' || where_clause_in, DBMS_SQL.NATIVE); /* Define the columns in the cursor for this query */ DBMS_SQL.DEFINE_COLUMN (c, 1, emprec.empno); DBMS_SQL.DEFINE_COLUMN (c, 2, emprec.ename, 30); /* Now I can execute the query */ fdbk:= DBMS_SQL.EXECUTE (c); LOOP /* Try to fetch next row. If done, then exit the loop. */ EXIT WHEN DBMS_SQL.FETCH_ROWS (c) = 0; /* || Retrieve data via calls to COLUMN_VALUE and place those || values in a new record in the block. */ DBMS_SQL.COLUMN_VALUE (c, 1, emprec.empno); DBMS_SQL.COLUMN_VALUE (c, 2, emprec.ename); CREATE_RECORD; :employee.employee_id := emprec.empno; :employee.employee_nm := emprec.ename; END LOOP; /* Clean up the cursor */ DBMS_SQL.CLOSE_CURSOR (c); END;
In this example, you can fetch only one row at a time, because you defined each of your columns in the cursor to hold a single value. If, on the other hand, you defined a column as an array, then the fetch could receive multiple rows in a single call. This approach is explored in more detail in the section Section 2.5.6, "Array Processing with DBMS_SQL"."
The EXECUTE_AND_FETCH function executes the SELECT statement associated with the specified cursor and immediately fetches the rows associated with the query. Here's the specification for the function.
FUNCTION DBMS_SQL.EXECUTE_AND_FETCH
(c IN INTEGER
,exact IN BOOLEAN DEFAULT FALSE)
RETURN INTEGER;
Parameters are summarized in the following table.
Parameter | Description |
|---|---|
c | The handle or pointer to the cursor originally returned by a call to OPEN_CURSOR. |
exact | Set to TRUE if you want the function to raise an exception when it fetches more than one row. |
Even if EXECUTE_AND_FETCH does raise an exception (TOO_MANY_ROWS), the rows will still be fetched and available. The value returned by the function will, however, be NULL.
This function is designed to make it easy to execute and fetch a single row from a query. It is very similar to the implicit SELECT cursor in native PL/SQL, which either returns a single row, multiple rows (for PL/SQL8 array access only), or raises the TOO_MANY_ROWS exception (ORA-01422).
See the sidebar entitled the sidebar "Oracle: The Show Me Technology"," for a script you can use to examine the behavior of this built-in function.
If you construct a dynamic SELECT or PL/SQL block, you can retrieve values from the cursor after execution. Use the COLUMN_VALUE procedure to obtain the values of individual columns in the fetched row of a SELECT. Use the COLUMN_VALUE_LONG procedure to obtain the values of a LONG column in the fetched row of a SELECT. Use the VARIABLE_VALUE procedure to extract the values of variables in a dynamic PL/SQL block.
The COLUMN_VALUE procedure retrieves a value from the cursor into a local variable. Use this procedure when the SQL statement is a query and you are fetching rows with EXECUTE_AND_FETCH or FETCH_ROWS. You can retrieve the value for a single column in a single row or, with PL/SQL8, you can retrieve the values for a single column across multiple rows fetched. The header for the single-row version of the procedure is as follows:
PROCEDURE DBMS_SQL.COLUMN_VALUE
(c IN INTEGER,
position IN INTEGER,
value OUT <datatype>,
[, column_error OUT NUMBER]
[, actual_length OUT INTEGER ]);The COLUMN_VALUE parameters are summarized in the following table.
Parameter | Description |
|---|---|
c | Pointer to the cursor. |
position | Relative position of the column in the select list. |
value | The PL/SQL structure that receives the column value. If the <datatype> of this argument does not match that of the cursor's column, DBMS_SQL will raise the DBMS_SQL.INCONSISTENT_DATATYPE exception. |
<table_parameter> | The PL/SQL table (of type <table_type>) holding one or more colum values, depending on how many rows were previously fetched. |
column_error | Returns an error code for the specified value (the value might be too large for the variable, for instance). |
actual_length | Returns the actual length of the returned value before any truncation takes place (due to a difference in size between the retrieved value in the cursor and the variable). |
<datatype> can be one of the following types:
NUMBER DATE MLSLABEL VARCHAR2 CHARACTER SET ANY_CS BLOB CLOB CHARACTER SET ANY_CS BFILE
The header for the multiple-row version of COLUMN_VALUE is as follows:
PROCEDURE DBMS_SQL.COLUMN_VALUE
(c IN INTEGER,
position IN INTEGER,
<table_parameter> OUT <table_type>);<table_parameter> OUT <table_type> can be one of the following:
n_tab OUT DBMS_SQL.NUMBER_TABLE c_tab OUT DBMS_SQL.VARCHAR2_TABLE d_tab OUT DBMS_SQL.DATE_TABLE bl_tab OUT DBMS_SQL.BLOB_TABLE cl_tab OUT DBMS_SQL.CLOB_TABLE bf_tab OUT DBMS_SQL.BFILE_TABLE
The DBMS_SQL package also offers more specific variants of COLUMN_VALUE for less common datatype:
PROCEDURE DBMS_SQL.COLUMN_VALUE_CHAR (c IN INTEGER, position IN INTEGER, value OUT CHAR, [, column_error OUT NUMBER] [, actual_length OUT INTEGER ]); PROCEDURE DBMS_SQL.COLUMN_VALUE_RAW (c IN INTEGER, position IN INTEGER, value OUT RAW, [, column_error OUT NUMBER] [, actual_length OUT INTEGER ]); PROCEDURE DBMS_SQL.COLUMN_VALUE_ROWID (c IN INTEGER, position IN INTEGER, value OUT ROWID, [, column_error OUT NUMBER] [, actual_length OUT INTEGER ]);
You call COLUMN_VALUE after a row has been fetched to transfer the value from the SELECT list of the cursor into a local variable. For each call to the single-row COLUMN_VALUE, you should have made a call to DEFINE_COLUMN in order to define that column in the cursor. If you want to use the multiple-row version of COLUMN_VALUE, use the DEFINE_ARRAY procedure to define that column as capable of holding an array of values.
The following procedure displays employees by defining a cursor with two columns and, after fetching a row, calls COLUMN_VALUE to retrieve both column values:
/* Filename on companion disk: showemps.sp */ CREATE OR REPLACE PROCEDURE showemps (where_in IN VARCHAR2 := NULL) IS cur INTEGER := DBMS_SQL.OPEN_CURSOR; rec emp%ROWTYPE; fdbk INTEGER; BEGIN DBMS_SQL.PARSE (cur, 'SELECT empno, ename FROM emp ' || ' WHERE ' || NVL (where_in, '1=1'), DBMS_SQL.NATIVE); DBMS_SQL.DEFINE_COLUMN (cur, 1, rec.empno); DBMS_SQL.DEFINE_COLUMN (cur, 2, rec.ename, 30); fdbk := DBMS_SQL.EXECUTE (cur); LOOP /* Fetch next row. Exit when done. */ EXIT WHEN DBMS_SQL.FETCH_ROWS (cur) = 0; DBMS_SQL.COLUMN_VALUE (cur, 1, rec.empno); DBMS_SQL.COLUMN_VALUE (cur, 2, rec.ename); DBMS_OUTPUT.PUT_LINE (TO_CHAR (rec.empno) || '=' || rec.ename); END LOOP; DBMS_SQL.CLOSE_CURSOR (cur); END; /
This next PL/SQL8 block fetches the hiredate and employee ID for all rows in the emp table and deposits values into two separate PL/SQL tables. Notice that since I know there are just 14 rows in the emp table, I need only one call to the EXECUTE_AND_FETCH function to fetch all rows.
/* Filename on companion disk: arrayemp.sp */ CREATE OR REPLACE PROCEDURE showall IS cur INTEGER := DBMS_SQL.OPEN_CURSOR; fdbk INTEGER; empno_tab DBMS_SQL.NUMBER_TABLE; hiredate_tab DBMS_SQL.DATE_TABLE; BEGIN DBMS_SQL.PARSE (cur, 'SELECT empno, hiredate FROM emp', DBMS_SQL.NATIVE); /* Allow fetching of up to 100 rows. */ DBMS_SQL.DEFINE_ARRAY (cur, 1, empno_tab, 100, 1); DBMS_SQL.DEFINE_ARRAY (cur, 2, hiredate_tab, 100, 1); fdbk := DBMS_SQL.EXECUTE_AND_FETCH (cur); /* This will show total numbers of rows fetched. */ DBMS_OUTPUT.PUT_LINE (fdbk); /* Get values for all rows in one call. */ DBMS_SQL.COLUMN_VALUE (cur, 1, empno_tab); DBMS_SQL.COLUMN_VALUE (cur, 2, hiredate_tab); FOR rowind IN empno_tab.FIRST .. empno_tab.LAST LOOP DBMS_OUTPUT.PUT_LINE (empno_tab(rowind)); DBMS_OUTPUT.PUT_LINE (hiredate_tab(rowind)); END LOOP; DBMS_SQL.CLOSE_CURSOR (cur); END; /
The Section 2.5, "DBMS_SQL Examples"" section provides other examples of array processing in DBMS_SQL.
DBMS_SQL provides a separate procedure, COLUMN_VALUE_LONG, to allow you to retrieve LONG values from a dynamic query. The header for this program is as follows:
PROCEDURE DBMS_SQL.COLUMN_VALUE_LONG
(c IN INTEGER
,position IN INTEGER
,length IN INTEGER
,offset IN INTEGER
,value OUT VARCHAR2
,value_length OUT INTEGER);The COLUMN_VALUE_LONG parameters are summarized in the following table.
Parameter | Description |
|---|---|
c | Pointer to the cursor. |
position | Relative position of the column in the select list. |
length | The length in bytes of the portion of the LONG value to be retrieved. |
offset | The byte position in the LONG column at which the retrieval is to start. |
value | The variable that will receive part or all of the LONG column value. |
value_length | The actual length of the retrieved value. |
The COLUMN_VALUE_LONG procedure offers just about the only way to obtain a LONG value from the database and move it into PL/SQL data structures in your program. You cannot rely on a static SELECT to do this. Instead, use DBMS_SQL and both the DEFINE_COLUMN_LONG and COLUMN_VALUE_LONG procedures.
The following example demonstrates the technique, and, in the process, offers a generic procedure called dump_long that you can use to dump the contents of a long column in your table into a local PL/SQL table. The dump_long procedure accepts a table name, column name, and optional WHERE clause. It returns a PL/SQL table with the LONG value broken up into 256-byte chunks.
/* Filename on companion disk: dumplong.sp */ CREATE OR REPLACE PROCEDURE dump_long ( tab IN VARCHAR2, col IN VARCHAR2, whr IN VARCHAR2 := NULL, pieces IN OUT DBMS_SQL.VARCHAR2S) /* Requires Oracle 7.3 or above */ IS cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR; fdbk PLS_INTEGER; TYPE long_rectype IS RECORD ( piece_len PLS_INTEGER, pos_in_long PLS_INTEGER, one_piece VARCHAR2(256), one_piece_len PLS_INTEGER ); rec long_rectype; BEGIN if whr is NULL */ DBMS_SQL.PARSE ( cur, 'SELECT ' || col || ' FROM ' || tab || ' WHERE ' || NVL (whr, '1 = 1'), DBMS_SQL.NATIVE); /* Define the long column and then execute and fetch... */ DBMS_SQL.DEFINE_COLUMN_LONG (cur, 1); fdbk := DBMS_SQL.EXECUTE (cur); fdbk := DBMS_SQL.FETCH_ROWS (cur); /* If a row was fetched, loop through the long value until || all pieces are retrieved. */ IF fdbk > 0 THEN rec.piece_len := 256; rec.pos_in_long := 0; LOOP DBMS_SQL.COLUMN_VALUE_LONG ( cur, 1, rec.piece_len, rec.pos_in_long, rec.one_piece, rec.one_piece_len); EXIT WHEN rec.one_piece_len = 0; /* Always put the new piece in the next available row */ pieces (NVL (pieces.LAST, 0) + 1) := rec.one_piece; rec.pos_in_long := rec.pos_in_long + rec.one_piece_len; END LOOP; END IF; DBMS_SQL.CLOSE_CURSOR (cur); END; /
To test this procedure, I created a table with a LONG column as follows (the table creation, INSERT, and test script may all be found in dumplong.tst):
DROP TABLE nextbook;
CREATE TABLE nextbook
(title VARCHAR2(100), text LONG);
INSERT INTO nextbook VALUES
('Oracle PL/SQL Quick Reference',
RPAD ('INSTR ', 256, 'blah1 ') ||
RPAD ('SUBSTR ', 256, 'blah2 ') ||
RPAD ('TO_DATE ', 256, 'blah3 ') ||
RPAD ('TO_CHAR ', 256, 'blah4 ') ||
RPAD ('LOOP ', 256, 'blah5 ') ||
RPAD ('IF ', 256, 'blah6 ') ||
RPAD ('CURSOR ', 256, 'blah7 ')
);I then put together this short test script. It extracts the single value from the table. (I pass a NULL WHERE clause, so it simply returns the first -- and only -- row fetched.) It then uses a numeric FOR loop to scan through the returned table to display the results.
DECLARE
mytab DBMS_SQL.VARCHAR2S;
BEGIN
dump_long ('nextbook', 'text', NULL, mytab);
FOR longind IN 1 .. mytab.COUNT
LOOP
DBMS_OUTPUT.PUT_LINE (SUBSTR (mytab(longind), 1, 60));
END LOOP;
END;
/Here is the output displayed in my SQL*Plus window:
INSTR blah1 blah1 blah1 blah1 blah1 blah1 blah1 blah1 blah1 SUBSTR blah2 blah2 blah2 blah2 blah2 blah2 blah2 blah2 blah2 TO_DATE blah3 blah3 blah3 blah3 blah3 blah3 blah3 blah3 blah TO_CHAR blah4 blah4 blah4 blah4 blah4 blah4 blah4 blah4 blah LOOP blah5 blah5 blah5 blah5 blah5 blah5 blah5 blah5 blah5 b IF blah6 blah6 blah6 blah6 blah6 blah6 blah6 blah6 blah6 bla CURSOR blah7 blah7 blah7 blah7 blah7 blah7 blah7 blah7 blah7
The VARIABLE_VALUE procedure retrieves the value of a named variable from the specified PL/SQL block. You can retrieve the value for a single variable, or, with PL/SQL8, you can retrieve the values for an array or PL/SQL table of values. This is the header for the single-row version of the procedure:
PROCEDURE DBMS_SQL.VARIABLE_VALUE
(c IN INTEGER
,name IN VARCHAR2
,value OUT <datatype>);The VARIABLE_VALUE parameters are summarized in the following table.
Parameter | Description |
|---|---|
c | The handle or pointer to the cursor originally returned by a call to OPEN_CURSOR. |
name | The name of the host variable included in the PL/SQL statement passed to PARSE. |
value | The PL/SQL data structure (either a scalar variable, <datatype>, or a PL/SQL table, <table_type>) that receives the value from the cursor. |
<datatype> can be one of the following:
NUMBER DATE MLSLABEL VARCHAR2 CHARACTER SET ANY_CS BLOB CLOB CHARACTER SET ANY_CS BFILE
The header for the multiple-row version of VARIABLE_VALUE is the following:
PROCEDURE DBMS_SQL.VARIABLE_VALUE
(c IN INTEGER
,name IN VARCHAR2
,value IN <table_type>);<table_type> can be one of the following:
DBMS_SQL.NUMBER_TABLE DBMS_SQL.VARCHAR2_TABLE DBMS_SQL.DATE_TABLE DBMS_SQL.BLOB_TABLE DBMS_SQL.CLOB_TABLE DBMS_SQL.BFILE_TABLE
The DBMS_SQL package also offers more specific variants of VARIABLE_VALUE for less common datatypes:
PROCEDURE DBMS_SQL.VARIABLE_VALUE_CHAR
(c IN INTEGER
,name IN VARCHAR2
,value OUT CHAR CHARACTER SET ANY_CS);
PROCEDURE DBMS_SQL.VARIABLE_VALUE_RAW
(c IN INTEGER
,name IN VARCHAR2
,value OUT RAW);
PROCEDURE DBMS_SQL.VARIABLE_VALUE_ROWID
(c IN INTEGER
,name IN VARCHAR2
,value OUT ROWID);If you use the multiple-row version of VARIABLE_VALUE, you must have used the BIND_ARRAY procedure to define the bind variable in the PL/SQL block as an array of values.
The following program allows you to provide the name of a stored procedure, a list of IN parameters, and a single OUT variable. It then uses dynamic PL/SQL to construct and execute that stored procedure, and finally retrieves the OUT value and returns it to the calling block.
/* Filename on companion disk: runprog.sp */ CREATE OR REPLACE PROCEDURE runproc (proc IN VARCHAR2, arglist IN VARCHAR2, outval OUT NUMBER) IS cur INTEGER := DBMS_SQL.OPEN_CURSOR; fdbk INTEGER; BEGIN DBMS_SQL.PARSE (cur, 'BEGIN ' || proc || '(' || arglist || ', :outparam); END;', DBMS_SQL.NATIVE); DBMS_SQL.BIND_VARIABLE (cur, 'outparam', 1); fdbk := DBMS_SQL.EXECUTE (cur); DBMS_SQL.VARIABLE_VALUE (cur, 'outparam', outval); DBMS_SQL.CLOSE_CURSOR (cur); END; /
Now if I have the following procedure defined:
CREATE OR REPLACE PROCEDURE testdyn (in1 IN NUMBER, in2 IN DATE, out1 OUT NUMBER) IS BEGIN out1 := in1 + TO_NUMBER (TO_CHAR (in2, 'YYYY')); END; /
Then I can execute testdyn dynamically as follows:
DECLARE
n NUMBER;
BEGIN
runproc ('testdyn', '1, sysdate', n);
DBMS_OUTPUT.PUT_LINE (n);
END;
/As you have likely discerned, this is not a very good general-purpose program. It will work only with procedures that have parameter lists in which the last argument is a numeric OUT parameter and that argument must be the only OUT or IN OUT parameter in the list.
There can be many complications when attempting to execute dynamic PL/SQL. For suggestions on how best to perform these tasks, see the "Tips on Using Dynamic SQL" section.
When you are done working with a cursor, you should close it and release associated memory.
The CLOSE_CURSOR procedure closes the specified cursor and sets the cursor handle to NULL. It releases all memory associated with the cursor. The specification for the procedure is,
PROCEDURE DBMS_SQL.CLOSE_CURSOR (c IN OUT INTEGER);
where c is the handle or pointer to the cursor that was originally returned by a call to OPEN_CURSOR. The parameter is IN OUT because once the cursor is closed, the pointer is set to NULL.
If you try to close a cursor that is not open or that is not a valid cursor ID, this program will raise the INVALID_CURSOR exception. You might consider building a "wrapper" for CLOSE_CURSOR to avoid this exception.
CREATE OR REPLACE PROCEDURE closeif (c IN OUT INTEGER)
IS
BEGIN
IF DBMS_SQL.IS_OPEN (c)
THEN
DBMS_SQL.CLOSE_CURSOR (c);
END IF;
END;
/Several functions allow you to check the status of a cursor.
The LAST_ERROR_POSITION function returns the byte offset in the SQL statement where the error occurred. The first character in the statement is at position 0. This function offers the same kind of feedback SQL*Plus offers you when it displays a syntax or value error while executing a SQL statement: it displays the problematic text with an asterisk (*) under the character that caused the problem. Here's the specification for this function:
FUNCTION DBMS_SQL.LAST_ERROR RETURN INTEGER;
You must call this function immediately after a call to EXECUTE or EXECUTE_AND_FETCH in order to obtain meaningful results. The following script demonstrates when and how this function's return value can come in handy:
/* Filename on companion disk: file errpos.sql */* DECLARE cur BINARY_INTEGER := DBMS_SQL.OPEN_CURSOR; errpos BINARY_INTEGER; fdbk BINARY_INTEGER; BEGIN DBMS_SQL.PARSE (cur, 'SELECT empno, ^a FROM emp', DBMS_SQL.NATIVE); DBMS_SQL.DEFINE_COLUMN (cur, 1, 1); fdbk := DBMS_SQL.EXECUTE_AND_FETCH (cur, false); DBMS_SQL.CLOSE_CURSOR (cur); EXCEPTION WHEN OTHERS THEN errpos := DBMS_SQL.LAST_ERROR_POSITION; DBMS_OUTPUT.PUT_LINE (SQLERRM || ' at pos ' || errpos); DBMS_SQL.CLOSE_CURSOR (cur); END; /
When I run this script in SQL*Plus, I get the following output:
SQL> @errpos ORA-00936: missing expression at pos 14
One of the greatest frustrations with dynamic SQL is getting your string strung together improperly. It is very easy to introduce syntax errors. The DBMS_SQL.LAST_ERROR_POSITION function can be a big help in uncovering the source of your problem.
NOTE: Some readers may be wondering why I declared a local variable called errpos and assigned the value to it before calling DBMS_OUTPUT.PUT_LINE to examine the error. The reason (discovered by Eric Givler, ace technical reviewer for this book) is that if I do not grab the value from this function before calling SQLERRM, the function will return 0 instead of the 14 for which I am looking.
If my exception section looks, for example, as follows,
WHEN OTHERS
THEN
DBMS_OUTPUT.PUT_LINE
(SQLERRM || ' at pos ' || DBMS_SQL.LAST_ERROR_POSITION);
DBMS_SQL.CLOSE_CURSOR (cur);then the output from running the program will become:
SQL> @errpos ORA-00936: missing expression at pos 0
Why does this happen? The SQLERRM function must be executing an implicit SQL statement (probably a query!). This action resets the values returned by this DBMS_SQL function, since it is tied to the underlying, generic implicit cursor attribute.
The LAST_ROW_COUNT function returns the total number of rows fetched at that point. This function corresponds to the %ROWCOUNT attribute of a normal, static cursor in PL/SQL. Here's the specification for this function:
FUNCTION DBMS_SQL.LAST_ROW_COUNT RETURN INTEGER;
You must call this function immediately after a call to EXECUTE_AND_FETCH or FETCH_ROWS in order to obtain meaningful results. You will most likely use this function when fetching from within a loop:
CREATE OR REPLACE PROCEDURE show_n_emps (lim IN INTEGER)
IS
cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR;
fdbk PLS_INTEGER;
v_ename emp.ename%TYPE;
BEGIN
DBMS_SQL.PARSE (cur, 'SELECT ename FROM emp', DBMS_SQL.NATIVE);
DBMS_SQL.DEFINE_COLUMN (cur, 1, v_ename, 100);
fdbk := DBMS_SQL.EXECUTE (cur);
LOOP
EXIT WHEN DBMS_SQL.FETCH_ROWS (cur) = 0;
IF DBMS_SQL.LAST_ROW_COUNT <= lim
THEN
DBMS_SQL.COLUMN_VALUE (cur, 1, v_ename);
DBMS_OUTPUT.PUT_LINE (v_ename);
ELSE
/* Hit maximum. Display message and exit. */
DBMS_OUTPUT.PUT_LINE
('Displayed ' || TO_CHAR (lim) || ' employees.');
EXIT;
END IF;
END LOOP;
DBMS_SQL.CLOSE_CURSOR (cur);
END;
/The LAST_ROW_ID function returns the ROWID of the row fetched most recently. The specification for this function is as follows:
FUNCTION DBMS_SQL.LAST_ROW_ID RETURN ROWID;
You must call this function immediately after a call to EXECUTE_AND_FETCH or FETCH_ROWS in order to obtain meaningful results. This function is useful mostly for debugging purposes and perhaps to log which records have been affected.
The LAST_SQL_FUNCTION_CODE function returns the SQL function code for the SQL statement. The specification for this function is as follows:
FUNCTION DBMS_SQL.LAST_SQL_FUNCTION_CODE RETURN INTEGER;
You must call this function immediately after a call to EXECUTE_AND_FETCH or EXECUTE in order to obtain meaningful results. It will tell you which type of SQL statement was executed.
The SQL function codes are listed in Table 2.3.
Code | SQL Function | Code | SQL Function | Code | SQL Function |
|---|---|---|---|---|---|
01 | CREATE TABLE | 35 | LOCK | 69 | (NOT USED) |
02 | SET ROLE | 36 | NOOP | 70 | ALTER RESOURCE COST |
03 | INSERT | 37 | RENAME | 71 | CREATE SNAPSHOT LOG |
04 | SELECT | 38 | COMMENT | 72 | ALTER SNAPSHOT LOG |
05 | UPDATE | 39 | AUDIT | 73 | DROP SNAPSHOT LOG |
06 | DROP ROLE | 40 | NO AUDIT | 74 | CREATE SNAPSHOT |
07 | DROP VIEW | 41 | ALTER INDEX | 75 | ALTER SNAPSHOT |
08 | DROP TABLE | 42 | CREATE EXTERNAL DATABASE | 76 | DROP SNAPSHOT |
09 | DELETE | 43 | DROP EXTERNAL DATABASE | 77 | CREATE TYPE |
10 | CREATE VIEW | 44 | CREATE DATABASE | 78 | DROP TYPE |
11 | DROP USER | 45 | ALTER DATABASE | 79 | ALTER ROLE |
12 | CREATE ROLE | 46 | CREATE ROLLBACK SEGMENT | 80 | ALTER TYPE |
13 | CREATE SEQUENCE | 47 | ALTER ROLLBACK SEGMENT | 81 | CREATE TYPE BODY |
14 | ALTER SEQUENCE | 48 | DROP ROLLBACK SEGMENT | 82 | ALTER TYPE BODY |
15 | (NOT USED) | 49 | CREATE TABLESPACE | 83 | DROP TYPE BODY |
16 | DROP SEQUENCE | 50 | ALTER TABLESPACE | 84 | DROP LIBRARY |
17 | CREATE SCHEMA | 51 | DROP TABLESPACE | 85 | TRUNCATE TABLE |
18 | CREATE CLUSTER | 52 | ALTER SESSION | 86 | TRUNCATE CLUSTER |
19 | CREATE USER | 53 | ALTER USER | 87 | CREATE BITMAPFILE |
20 | CREATE INDEX | 54 | COMMIT (WORK) | 88 | ALTER VIEW |
21 | DROP INDEX | 55 | ROLLBACK | 89 | DROP BITMAPFILE |
22 | DROP CLUSTER | 56 | SAVEPOINT | 90 | SET CONSTRAINTS |
23 | VALIDATE INDEX | 57 | CREATE CONTROL FILE | 91 | CREATE FUNCTION |
24 | CREATE PROCEDURE | 58 | ALTER TRACING | 92 | ALTER FUNCTION |
25 | ALTER PROCEDURE | 59 | CREATE TRIGGER | 93 | DROP FUNCTION |
26 | ALTER TABLE | 60 | ALTER TRIGGER | 94 | CREATE PACKAGE |
27 | EXPLAIN | 61 | DROP TRIGGER | 95 | ALTER PACKAGE |
28 | GRANT | 62 | ANALYZE TABLE | 96 | DROP PACKAGE |
29 | REVOKE | 63 | ANALYZE INDEX | 97 | CREATE PACKAGE BODY |
30 | CREATE SYNONYM | 64 | ANALYZE CLUSTER | 98 | ALTER PACKAGE BODY |
31 | DROP SYNONYM | 65 | CREATE PROFILE | 99 | DROP PACKAGE BODY |
32 | ALTER SYSTEM SWITCH LOG | 66 | DROP PROFILE | 157 | CREATE DIRECTORY |
33 | SET TRANSACTION | 67 | ALTER PROFILE | 158 | DROP DIRECTORY |
34 | PL/SQL EXECUTE | 68 | DROP PROCEDURE | 159 | CREATE LIBRARY |
With PL/SQL8, you can now obtain information about the structure of the columns of your dynamic cursor.
The DESCRIBE_COLUMNS procedure obtains information about your dynamic cursor. Here is the header:
PROCEDURE DBMS_SQL.DESCRIBE_COLUMNS
(c IN INTEGER
,col_cnt OUT INTEGER
,desc_t OUT DBMS_SQL.DESC_TAB);The parameters for the DESCRIBE_COLUMNS procedure are summarized in the following table.
Parameter | Description |
|---|---|
c | The pointer to the cursor. |
col_cnt | The number of columns in the cursor, which equals the number of rows defined in the PL/SQL table. |
desc_t | The PL/SQL table, which contains all of the column information. This is a table of records of type DBMS_SQL.DESC_REC (<table_type), which is described later. |
The following table lists the DBMS_SQL.DESC_REC record type fields.
<table_type> | Datatype | Description |
|---|---|---|
col_type | BINARY_INTEGER | Type of column described |
col_max_len | BINARY_INTEGER | Maximum length of column value |
col_name | VARCHAR2(32) | Name of the column |
col_name_len | BINARY_INTEGER | Length of the column name |
col_schema_name | VARCHAR2(32) | Name of column type schema if an object type |
col_schema_name_len | BINARY_INTEGER | Length of schema name |
col_precision | BINARY_INTEGER | Precision of column if a number |
col_scale | BINARY_INTEGER | Scale of column if a number |
col_charsetid | BINARY_INTEGER | ID of character set |
col_charsetform | BINARY_INTEGER | Character set form |
col_null_ok | BOOLEAN | TRUE if column can be NULL |
The values for column types are as follows:
Datatype | Number |
|---|---|
VARCHAR2 | 1 |
NVARCHAR2 | 1 |
NUMBER | 2 |
INTEGER | 2 |
LONG | 8 |
ROWID | 11 |
DATE | 12 |
RAW | 23 |
LONG RAW | 24 |
CHAR | 96 |
NCHAR | 96 |
MLSLABEL | 106 |
CLOB (Oracle8) | 112 |
NCLOB (Oracle8) | 112 |
BLOB (Oracle8) | 113 |
BFILE (Oracle8) | 114 |
Object type (Oracle8) | 121 |
Nested table Type (Oracle8) | 122 |
Variable array (Oracle8) | 123 |
When you call this program, you need to have declared a PL/SQL table based on the DBMS_SQL.DESC_T. You can then use PL/SQL table methods to traverse the table and extract the needed information about the cursor. The following anonymous block shows the basic steps you will perform when working with this built-in:
DECLARE
cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR;
cols DBMS_SQL.DESC_T;
ncols PLS_INTEGER;
BEGIN
DBMS_SQL.PARSE
(cur, 'SELECT hiredate, sal FROM emp', DBMS_SQL.NATIVE);
DBMS_SQL.DEFINE_COLUMN (cur, 1, SYSDATE);
DBMS_SQL.DEFINE_COLUMN (cur, 2, 1);
DBMS_SQL.DESCRIBE_COLUMNS (cur, ncols, cols);
FOR colind IN 1 .. ncols
LOOP
DBMS_OUTPUT.PUT_LINE (cols.col_name);
END LOOP;
DBMS_SQL.CLOSE_CURSOR (cur);
END;
/If you are going to use this procedure to extract information about a dynamic cursor, you will likely want to build a "wrapper" around it to make it easier for you to get at this data. The Section 2.5" section at the end of this chapter offers an example of this wrapper.
|  | |
| 2.2 Getting Started with DBMS_SQL |  | 2.4 Tips on Using Dynamic SQL |
Copyright (c) 2000 O'Reilly & Associates. All rights reserved.