 | Chapter 11 |  |

| Chapter 11 | |
A character function is a function that takes one or more character values as parameters and returns either a character value or a number value. The Oracle Server and PL/SQL provide a number of different character datatypes, including CHAR, VARCHAR, VARCHAR2, LONG, RAW, and LONG RAW. In PL/SQL, the three different datatype families for character data are:
A variable-length character datatype whose data is converted by the RDBMS
The fixed-length datatype
A variable-length datatype whose data is not converted by the RDBMS, but instead is left in "raw" form
When a character function returns a character value, that value is always of type VARCHAR2 (variable length), with the following two exceptions: UPPER and LOWER. These functions convert to upper- and lowercase, respectively, and return CHAR values (fixed length) if the strings they are called on to convert are fixed-length CHAR arguments.
PL/SQL provides a rich set of character functions that allow you to get information about strings and modify the contents of those strings in very high-level, powerful ways. Table 11.1 shows the character functions covered in detail in this chapter. The remaining functions (not covered in this chapter) are specific to National Language Support and Trusted Oracle.
| Name | Description |
|---|---|
| ASCII | Returns the ASCII code of a character. |
| CHR | Returns the character associated with the specified collating code. |
| CONCAT | Concatenates two strings into one. |
| INITCAP | Sets the first letter of each word to uppercase. All other letters are set to lowercase. |
| INSTR | Returns the location in a string of the specified substring. |
| LENGTH | Returns the length of a string. |
| LOWER | Converts all letters to lowercase. |
| LPAD | Pads a string on the left with the specified characters. |
| LTRIM | Trims the left side of a string of all specified characters. |
| REPLACE | Replaces a character sequence in a string with a different set of characters. |
| RPAD | Pads a string on the right with the specified characters. |
| RTRIM | Trims the right side of a string of all specified characters. |
| SOUNDEX | Returns the "soundex" of a string. |
| SUBSTR | Returns the specified portion of a string. |
| TRANSLATE | Translates single characters in a string to different characters. |
| UPPER | Converts all letters in the string to uppercase. |
The following sections briefly describe each of the PL/SQL character functions.
The ASCII function returns the NUMBER code that represents the specified character in the database character set. The specification of the ASCII function is:
FUNCTION ASCII (single_character IN VARCHAR2) RETURN NUMBER
where single_character is the character to be located in the collating sequence. Even though the function is named ASCII, it will return the code location in whatever the database character set is set to, such as EBCDIC Code Page 500 or 7-bit ASCII. For example, in the 7-bit ASCII character set, ASCII (`a') returns 97. Remember that the collating code for uppercase letters is different from that for lowercase letters. ASCII (`A') returns 65 (in the 7-bit ASCII character set) because the uppercase letters come before the lowercase letters in the sequence.
If you pass more than one character in the parameter to ASCII, it returns the collating code for the first character and ignores the other characters. As a result, the following calls to ASCII all return the same value of 100:
ASCII ('defg') ==> 100
ASCII ('d') ==> 100
ASCII ('d_e_f_g') ==> 100The CHR function is the inverse of ASCII. It returns a VARCHAR2 character (length 1) that corresponds to the location in the collating sequence provided as a parameter. The specification of the CHR function is:
FUNCTION CHR (code_location IN NUMBER) RETURN VARCHAR2
where code_location is the number specifying the location in the collating sequence.
The CHR function is especially valuable when you need to make reference to a nonprintable character in your code. For example, the location in the standard ASCII collating sequence for the newline character is ten. The CHR function therefore gives me a way to search for the linefeed control character in a string, and perform operations on a string based on the presence of that control character.
You can also insert a linefeed into a character string using the CHR function. Suppose I have to build a report that displays the address of a company. A company can have up to four address strings (in addition to city, state, and zipcode). I need to put each address string on a new line, but I don't want any blank lines embedded in the address. The following SELECT will not do the trick:
SELECT name, address1, address2, address3, address4,
city || ', ' || state || ' ' || zipcode location
FROM company;Assuming each column (report field) goes on a new line, you will end up using six lines per address, no matter how many of these address strings are NULL. For example:
HAROLD HENDERSON 22 BUNKER COURT SUITE 100 WYANDANCH, MN 66557
You can use the CHR function to suppress these internal blank lines as follows:
SELECT name ||
DECODE (address1, NULL, NULL, CHR (10) || address1) ||
DECODE (address2, NULL, NULL, CHR (10) || address2) ||
DECODE (address3, NULL, NULL, CHR (10) || address3) ||
DECODE (address4, NULL, NULL, CHR (10) || address4) ||
CHR (10) ||
city || ', ' || state || ' ' || zipcode
FROM company;Now the query returns a single formatted column per company. The DECODE statement offers IF-THEN logic within SQL and executes as follows: "If the address string is NULL then concatenate NULL; otherwise insert a linefeed character. Then concatenate the address string."
In this way, blank address lines are ignored. If I now use Wrap on the report field which holds this string, the address will be scrunched down to:
HAROLD HENDERSON 22 BUNKER COURT SUITE 100 WYANDANCH, MN 66557
The CONCAT function concatenates by taking two VARCHAR2 strings and returning those strings appended together in the order specified. The specification of the CONCAT function is:
FUNCTION CONCAT (string1 IN VARCHAR2, string2 IN VARCHAR2)
RETURN VARCHAR2CONCAT always appends string2 to the end of string1. If either string is NULL, CONCAT returns the non-NULL argument all by its lonesome. If both strings are NULL, CONCAT returns NULL. Here are some examples of uses of CONCAT:
CONCAT ('abc', 'defg') ==> 'abcdefg'
CONCAT (NULL, 'def') ==> 'def'
CONCAT ('ab', NULL) ==> 'ab'
CONCAT (NULL, NULL) ==> NULLI have a confession to make about CONCAT: I have never used it once in all my years of PL/SQL coding. In fact, I never even noticed it was available until I did the research for this book. How can this be? Did I never have to concatenate strings together in my programs? No, I certainly have performed many acts of concatenation in my time. Surprisingly, the answer is that PL/SQL (and the Oracle RDBMS) offers a second concatenation operator -- the double vertical bars (||). This operator is much more flexible and powerful and is easier to use than CONCAT.
The INITCAP function reformats the case of the string argument, setting the first letter of each word to uppercase and the remainder of the letters in that word to lowercase. A word is a set of characters separated by a space or nonalphanumeric characters (such as # or _ ). The specification of INITCAP is:
FUNCTION INITCAP (string_in IN VARCHAR2) RETURN VARCHAR2
Here are some examples of the impact of INITCAP on your strings:
Shift all lowercase to mixed case:
INITCAP ('this is lower') ==> 'This Is Lower'Shift all uppercase to mixed case:
INITCAP ('BIG>AND^TALL') ==> 'Big>And^Tall'Shift a confusing blend of cases to consistent initcap format:
INITCAP ('wHatISthis_MESS?') ==> 'Whatisthis_Mess?'Create Visual Basic-style variable names (I use REPLACE, explained later, to strip out the embedded spaces).
REPLACE (INITCAP ('ALMOST_UNREADABLE_VAR_NAME'), '_', NULL)
==>
'AlmostUnreadableVarName'When and why would you use INITCAP? Many Oracle shops like to store all character string data in the database, such as names and addresses, in uppercase. This makes it easier to search for records that match certain criteria.
The problem with storing all the data in uppercase is that, while it is a convenient "machine format," it is not particularly readable or presentable. How easy is it to scan a page of information that looks like the following?
CUSTOMER TRACKING LIST - GENERATED ON 12-MAR-1994 LAST PAYMENT WEDNESDAY: PAUL JOHNSON, 123 MADISON AVE - $1200 LAST PAYMENT MONDAY: HARRY SIMMERSON, 555 AXELROD RD - $1500
It is hard for the eye to pick out the individual words and different types of information; all that text just blends in together. Furthermore, solid uppercase simply has a "machine" or even "mainframe" feel to it; you'd never actually type it that way. A mixture of upper- and lowercase can make your output much more readable and friendly in appearance:
Customer Tracking List - Generated On 12-Mar-1994 Last Payment Wednesday: Paul Johnson, 123 Madison Ave - $1200 Last Payment Monday: Harry Simmerson, 555 Axelrod Rd - $1500
Can you see any problems with using INITCAP to format output? There are a couple of drawbacks to the way it works. First, as you saw earlier with the string "BIG AND TALL", INITCAP is not very useful for generating titles, since it doesn't know that little words like "and" and "the" should not be capitalized. That is a relatively minor problem compared with the second: INITCAP is completely ignorant of real-world surname conventions. Names with internal capital letters, in particular, cannot be generated with INITCAP. Consider the following example:
INITCAP ('HAMBURGERS BY THE BILLIONS AT MCDONALDS')
==>
'Hamburgers By The Billions At Mcdonalds'Use INITCAP with caution when printing reports or displaying data, since the information it produces may not always be formatted correctly.
The INSTR function searches a string to find a match for the substring and, if found, returns the position, in the source string, of the first character of that substring. If there is no match, then INSTR returns 0. In Oracle7, if nth_appearance is not positive (i.e., if it is 0 or negative), then INSTR always returns 1. In Oracle8, a value of 0 or a negative number for nth_appearance causes INSTR to raise the VALUE_ERROR exception.
The specification of the INSTR function is:
FUNCTION INSTR
(string1 IN VARCHAR2,
string2 IN VARCHAR2
[,start_position IN NUMBER := 1
[, nth_appearance IN NUMBER := 1]])
RETURN NUMBERwhere string1 is the string searched by INSTR for the position in which the nth_appearance of string2 is found. The start_position parameter is the position in the string where the search will start. It is optional and defaults to 1 (the beginning of string1). The nth_appearance parameter is also optional and also defaults to 1.
Both the start_position and nth_appearance parameters can be literals like 5 or 157, variables, or complex expressions, as follows:
INSTR (company_name, 'INC', (last_location + 5) * 10)
If start_position is negative, then INSTR counts back start_position number of characters from the end of the string and then searches from that point towards the beginning of the string for the nth match. Figure 11.1 illustrates the two directions in which INSTR searches, depending on the sign of the start_position parameter.
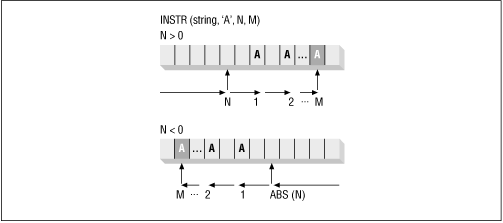
I have found INSTR to be a very handy function -- especially when used to the fullest extent possible. Most programmers make use of (and are even only aware of) only the first two parameters. Use INSTR to search from the end of the string? Search for the nth appearance, as opposed to just the first appearance? "Wow!" many programmers would say, "I didn't know it could do that." Take the time to get familiar with INSTR and use all of its power.
Let's look at some examples of INSTR. In these examples, you will see all four parameters used in all their permutations. As you write your own programs, keep in mind the different ways in which INSTR can be used to extract information from a string; it can greatly simplify the code you write to parse and analyze character data.
Find the first occurrence of archie in "bug-or-tv-character?archie":
INSTR ('bug-or-tv-character?archie', 'archie') ==> 21The starting position and the nth appearance both defaulted to 1.
Find the first occurrence of archie in the following string starting from position 14:
INSTR ('bug-or-tv-character?archie', 'ar', 14) ==> 21In this example I specified a starting position, which overrides the default of 1; the answer is still the same though. No matter where you start your search, the character position returned by INSTR is always calculated from the beginning of the string.
Find the second occurrence of archie in the following string:
INSTR ('bug-or-tv-character?archie', 'archie', 1, 2) ==> 0There is only one archie in the string, so INSTR returns 0. Even though the starting point is the default, I cannot leave it out if I also want to specify a nondefault nth appearance (2 in this case, for "second occurrence").
Find the second occurrence of "a" in "bug-or-tv-character?archie":
INSTR ('bug-or-tv-character?archie', 'a', 1, 2) ==> 15The second "a" in this string is the second "a" in "character," which is in the fifteenth position in the string.
Find the last occurrence of "ar" in "bug-or-tv-character?archie".
INSTR ('bug-or-tv-character?archie', 'ar', -1) ==> 21Were you thinking that the answer might be 6? Remember that the character position returned by INSTR is always calculated from the leftmost character of the string being position 1. The easiest way to find the last of anything in a string is to specify a negative number for the starting position. I did not have to specify the nth appearance (leaving me with a default value of 1), since the last occurrence is also the first when searching backwards.
Find the second-to-last occurrence of "a" in "bug-or-tv-character?archie":
INSTR ('bug-or-tv-character?archie', 'a', -1, 2) ==> 15No surprises here. Counting from the back of the string, INSTR passes over the "a" in archie, because that is the last occurrence, and searches for the next occurrence. Again, the character position is counted from the leftmost character, not the rightmost character, in the string.
Find the position of the letter "t" closest to (but not past) the question mark in the following string: bug-or-tv-character?archie tophat:
INSTR ('bug-or-tv-character?archie tophat', 't', -14) ==> 17I needed to find the "t" just before the question mark. The phrase "just before" indicates to me that I should search backwards from the question mark for the first occurrence. I therefore counted through the characters and determined that the question mark appears at the 20th position. I specified -14 as the starting position so that INSTR would search backwards right from the question mark.
What? Did I hear you mutter that I cheated? That if I could count through the string to find the question mark, I could just as well count through the string to find the closest "t"? I knew that I couldn't slip something like that by my readers.
A more general solution to the previous example: It is true that I "cheated." After all, when you are writing a program you usually do not know in advance the value and location of the string through which you are searching. It is likely to be a variable of some sort. It would be impossible to "count my way" to the question mark. Instead I need to find the location of the question mark and use that as the starting position. I need, in short, to use a second, or nested, INSTR inside the original INSTR. Here is a real solution to the problem:
search_string := 'bug-or-tv-character?archie tophat';
tee_loc :=
INSTR (search_string, 't',
-1 * (LENGTH (search_string) - INSTR (search_string, '?') +1));Instead of hardcoding 20 in my call to INSTR, I dynamically calculate the location of the question mark (actually, the first question mark in the string; I assume that there is only one). Then I subtract that from the full length of the string and multiply times -1 because I need to count the number of characters from the end of the string. I then use that value to kick off the search for the closest prior "t".
This example is a good reminder that any of the parameters to INSTR can be complex expressions that call other functions or perform their own calculations. This fact is also highlighted in the final INSTR example.
Use INSTR to confirm that a user entry is valid. In the code below, I check to see if the command selected by the user is found in the list of valid commands. If so, I execute that command:
IF INSTR ('|ADD|DELETE|CHANGE|VIEW|CALC|', '|' || cmd || '|') > 0
THEN
execute_command (cmd);
ELSE
DBMS_OUTPUT.PUT_LINE
(' You entered an invalid command. Please try again...');
END IF;In this case, I use the concatenation operator to construct the string that I will search for in the command list. I have to append a vertical bar (|) to the selected command because it is used as a delimiter in the command list. I also use the call to INSTR in a Boolean expression. If INSTR finds a match in the string, it returns a nonzero value. The Boolean expression therefore evaluates to TRUE and I can go on with my processing. Otherwise, I display an error message.
INSTR's flexibility allows you to write compact code which implements complex requirements. INSTRB is the multiple-byte character set version of INSTR. For single-byte character sets (such as American English), INSTRB returns the same values as INSTR.
The LENGTH function returns the length of the specified string. The specification for LENGTH follows:
FUNCTION LENGTH (string1 VARCHAR2) RETURN NUMBER
If string1 is NULL, then LENGTH returns NULL -- not zero (0)! Remember, a NULL string is a "nonvalue." Therefore, it cannot have a length, even a zero length.
The LENGTH function, in fact, will never return zero; it will always return either NULL or a positive number. Here are some examples:
LENGTH (NULL) ==> NULL
LENGTH ('') ==> NULL -- Same as a NULL string.
LENGTH ('abcd') ==> 4
LENGTH ('abcd ') ==> 5If string1 is a fixed-length CHAR datatype, then LENGTH counts the trailing blanks in its calculation. So the LENGTH of a fixed-length string is always the declared length of the string. If you want to compute the length of the nonblank characters in string1, you will need to use the RTRIM function to remove the trailing blanks (RTRIM is discussed later in this chapter). In the following example, length1 is set to 60 and length2 is set to 14.
DECLARE company_name CHAR(60) := 'ACME PLUMBING'; length1 NUMBER; length2 NUMBER; BEGIN length1 := LENGTH (company_name); length2 := LENGTH (RTRIM (company_name)); END;
LENGTHB is the multiple-byte character set version of LENGTH. For single-byte character sets (such as American English), LENGTH returns the same values as INSTR.
The LOWER function converts all letters in the specified string to lowercase. The specifications for the LOWER function are:
FUNCTION LOWER (string1 IN CHAR) RETURN CHAR FUNCTION LOWER (string1 IN VARCHAR2) RETURN VARCHAR2
As I noted earlier, LOWER and UPPER will actually return a fixed-length string if the incoming string is fixed-length. LOWER will not change any characters in the string that are not letters, since case is irrelevant for numbers and special characters, such as the dollar sign ($).
Here are some examples of the effect of LOWER:
LOWER ('BIG FAT LETTERS') ==> 'big fat letters'
LOWER ('123ABC') ==> '123abc'LOWER and its partner in case conversion, UPPER, are useful for guaranteeing a consistent case when comparing strings. PL/SQL is not a case-sensitive language with regard to its own syntax and names of identifiers. It is sensitive to case, however, in character strings, whether found in named constants, literals, or variables. The string "ABC" is not the same as "abc", and this can cause problems in your programs if you are not careful and consistent in your handling of such values.
By default, PL/SQL strips all trailing blanks from a character string unless it is declared with a fixed-length CHAR datatype. There are occasions, however, when you really want some spaces (or even some other character) added to the front or back of your string. LPAD (and its right-leaning cousin, RPAD) give you this capability. The LPAD function returns a string padded to the left (hence the "L" in "LPAD") to a specified length, and with a specified pad string. The specification of the LPAD function is:
FUNCTION LPAD
(string1 IN VARCHAR2,
padded_length IN NUMBER
[, pad_string IN VARCHAR2])
RETURN VARCHAR2LPAD returns string1 padded on the left to length padded_length with the optional character string pad_string. If you do not specify pad_string, then string1 is padded on the left with spaces. You must specify the padded_length. If string1 already has a length equal to padded_length, then LPAD returns string1 without any additional characters. If padded_length is smaller than the length of string1, LPAD effectively truncates string1 -- it returns only the first padded_length characters of the incoming string1.
As you can easily see, LPAD can do a lot more than just add spaces to the left of a string. Let's look at some examples of how useful LPAD can be.
Display the number padded left with zeros to a length of 10:
LPAD ('55', 10, '0') ==> '0000000055'Display the number padded left with zeros to a length of 5:
LPAD ('12345678', 5, '0') ==> '12345'LPAD interprets its padded_length as the maximum length of the string that it may return. As a result, it counts padded_length number of characters from the left (start of the string) and then simply returns that substring of the incoming value.
Place the phrase "sell!" in front of the names of selected stocks, up to a string length of 45:
LPAD ('HITOP TIES', 45, 'sell!')
==>
'sell!sell!sell!sell!sell!sell!sell!HITOP TIES'Because the length of "HITOP TIES" is 10 and the length of "sell!" is 5, there is room for seven repetitions of the pad string. LPAD does, in fact, generate a repetition of the pattern specified in the pad string.
Place the phrase "sell!" in front of the names of selected stocks, up to a string length of 43.
LPAD ('HITOP TIES', 43, 'sell!')
==>
'sell!sell!sell!sell!sell!sell!selHITOP TIES'Because the length of "HITOP TIES" is 10 and the length of "sell!" is 5, there is no longer room for seven full repetitions of the pad string. As a result, the seventh repetition (counting from the left) of "sell!" lost its last two characters. So you can see that LPAD does not pad by adding to the left of the original string until it runs out of room. Instead, it figures out how many characters it must pad by to reach the total, then constructs that full padded fragment, and finally appends the original string to this fragment.
Place three repetitions of the string "DRAFT-ONLY" in front of the article's title. Put two spaces between each repetition.
LPAD ('Why I Love PL/SQL', 53, 'DRAFT-ONLY ');
==>
'DRAFT-ONLY DRAFT-ONLY DRAFT-ONLY Why I Love PL/SQL'You can specify any number of characters to be padded in front of the incoming string value. The 53 that is hardcoded in that call to LPAD is the result of some hard calculations: the title is 17 characters and the prefix, including spaces, is 12 characters. As a result, I needed to make sure that I padded to a length of at least 17 + 12*3 = 53. This is not a very desirable way to solve the problem, however; once again I have assumed that in my program I have access to all these specific values and can precompute the length I need. The section entitled "Frame String with Prefix and Suffix" shows how to generalize this kind of action in a procedure -- without making any assumptions about lengths.
The LTRIM function is the opposite of LPAD. Whereas LPAD adds characters to the left of a string, LTRIM removes, or trims, characters from the leading portion of the string. And just as with LPAD, LTRIM offers much more flexibility than simply removing leading blanks. The specification of the LTRIM function is:
FUNCTION LTRIM (string1 IN VARCHAR2 [, trim_string IN VARCHAR2]) RETURN VARCHAR2
LTRIM returns string1 with all leading characters removed up to the first character not found in the trim_string. The second parameter is optional and defaults to a single space.
There is one important difference between LTRIM and LPAD. LPAD pads to the left with the specified string, and repeats that string (or pattern of characters) until there is no more room. LTRIM, on the other hand removes all leading characters which appear in the trim string, not as a pattern, but as individual candidates for trimming.
Here are some examples:
Trim all leading blanks from ` Way Out in Right Field':
LTRIM (' Way Out in Right Field') ==> 'Way Out in Right Field'Because I did not specify a trim string, it defaults to a single space and so all leading spaces are removed.
Trim `123' from the front of a string:
my_string := '123123123LotsaLuck123'; LTRIM (my_string, '123') ==> 'LotsaLuck123'
In this example, LTRIM stripped off all three leading repetitions of "123" from the specified string. Although it looks as though LTRIM trims by a specified pattern, this is not so, as the next example illustrates.
Remove all numbers from the front of the string:
my_string := '70756234LotsaLuck'; LTRIM (my_string, '0987612345') ==> 'LotsaLuck'
By specifying every possible digit in my trim string, I ensured that any and all numbers would be trimmed, regardless of the order in which they occurred (and the order in which I place them in the trim string).
Remove all a's, b's, and c's from the front of the string: `abcabcccccI LOVE CHILI':
LTRIM ('abcabcccccI LOVE CHILI', 'abc') ==> 'I LOVE CHILI'LTRIM removed the patterns of "abc", but also removed the individual instances of the letter "c". This worked out fine since the request was to remove any and all of those three letters. What if I wanted to remove only any instance of "abc" as a pattern from the front of the string? I couldn't use LTRIM since it trims off any matching individual characters. To remove a pattern from a string -- or to replace one pattern with another pattern -- you will want to make use of the REPLACE function, which is discussed next.
The REPLACE function returns a string in which all occurrences of a specified match string are replaced with a replacement string. REPLACE is useful for searching out patterns of characters and then changing all instances of that pattern in a single function call. The specification of the REPLACE function is:
FUNCTION REPLACE (string1 IN VARCHAR2, match_string IN VARCHAR2
[, replace_string IN VARCHAR2])
RETURN VARCHAR2If you do not specify the replacement string, then REPLACE simply removes all occurrences of the match_string in string1. If you specify neither a match string nor a replacement string, REPLACE returns NULL.
Here are several examples using REPLACE:
Remove all instances of the letter "C" in the string "CAT CALL":
REPLACE ('CAT CALL', 'C') ==> 'AT ALL'Because I did not specify a replacement string, REPLACE changed all occurrences of "C" to NULL.
Replace all occurrences of "99" with "100" in the following string:
REPLACE ('Zero defects in period 99 reached 99%!', '99', '100')
==>
'Zero defects in period 100 reached 100%!'Replace all occurrences of "th" with the letter "z":
REPLACE ('this that and the other', 'th', 'z') ==> 'zis zat and ze ozer'Handle occurrences of a single quote (') within a query criteria string. The single quote is a string terminator symbol. It indicates the start and/or end of the literal string. I ran into this requirement when building query-by-example strings in Oracle Forms. If the user enters a string with a single quote in it, such as:
Customer didn't have change.
and then I concatenate that string into a larger string, the resulting SQL statement (created dynamically by Oracle Forms in Query Mode) fails, because there are unbalanced single quotes in the string.
You can resolve this problem in one of three ways:
Simply strip out the single quote before you execute the query. This is workable only if there really aren't any single quotes in the data in the database.
If you do allow single quotes, you can then either replace the single quote with a single character wildcard ( _ ) or:
Embed that single quote inside other single quotes so that the SQL layer can properly parse the statement.
To replace the single quote with a wild card, you would code:
criteria_string := REPLACE (criteria_string, '''', '_');
That's right! Four single quotes in sequence are required for PL/SQL to understand that you want to search for one single quote in the criteria string. The first quote indicates the start of a literal. The fourth quote indicates the end of the string literal. The two inner single quotes parse into one single quote. That is, whenever you want to embed a single quote inside a literal, you must place another single quote before it.
This principle comes in handy for the final resolution of the single quote in query criteria problem: change the single quote to two single quotes and then execute the query.
criteria_string := REPLACE (criteria_string, '''', '''''');
as in:
REPLACE ('Customer didn''t have change.', '''', '''''')
==>
Customer didn''t have change.Now, even if you place single quotes at the beginning and end of this string, the internal single quote will not signal termination of the literal.
Remove all leading repetitions of "abc" from the string:
"abcabcccccI LOVE CHILIabc"
This is the behavior I was looking at in the previous section on LTRIM. I want to remove all instances of the pattern "abc" from the beginning of the string, but I do not want to remove that pattern throughout the rest of the string. In addition, I want to remove "abc" only as a pattern; if I encounter three contiguous c's ("ccc"), on the other hand, they should not be removed from the string. This task is less straightforward than it might at first seem. If I simply apply REPLACE to the string, it will remove all occurrences of "abc", instead of just the leading instances. For example:
REPLACE ('abcabccccI LOVE CHILIabc', 'abc') ==> 'cccI LOVE CHILI'That is not what I want in this case. If I use LTRIM, on the other hand, I will be left with none of the leading c's, as demonstrated in a previous example:
LTRIM ('abcabcccccI LOVE CHILIabc', 'abc') ==> 'I LOVE CHILIabc'And this is not quite right either. I want to be left with `cccI LOVE CHILIabc' (please do not ask why), and it turns out that the way to get it is to use a combination of LTRIM and REPLACE. Suppose I create a local variable as follows:
my_string := 'abcabccccI LOVE CHILIabc';
Then the following statement will achieve the desired effect by nesting calls to REPLACE and LTRIM within one another:
REPLACE
(LTRIM
(REPLACE (my_string, 'abc', '@'), '@'), '@', 'abc')
==>
'cccI LOVE CHILIabc'Here is how I would describe in English what the above statement does:
"First replace all occurrences of `abc' with the special character `@' (which I am assuming does not otherwise appear in the string). Then trim off all leading instances of `@'. Finally, replace all remaining occurrences of `@' with `abc'."
Voila, as they say in many of the finer restaurants in Paris. Now let's pull apart this single, rather complex statement into separate PL/SQL steps which correspond to my "natural language" description:
Replace all occurrences of "abc" with the special character "@" (which I am assuming does not otherwise appear in the string). Notice that this only affects the pattern and not any appearance of "a", "b", or "c".
REPLACE ('abcabccccI LOVE CHILIabc', 'abc', '@')
==> '@@cccI LOVE CHILI@'Trim off all leading instances of "@".
LTRIM ('@@cccI LOVE CHILI@', '@') ==> 'cccI LOVE CHILI@'Notice that LTRIM now leaves the c's in place, because I didn't ask it to remove `"a" or "b" or "c" -- just "@". In addition, it left the trailing "@" in the string since LTRIM deals only with characters on the leading end of the string.
Replace all remaining occurrences of "@" with "abc".
REPLACE ('cccI LOVE CHILI@', '@', 'abc') ==> 'cccI LOVE CHILIabc'And we are done. I used the first REPLACE to temporarily change the occurrences of "abc" so that LTRIM could distinguish between the pattern I wanted to get rid of and the extra characters which needed to be preserved. Then, a final call to REPLACE restored the pattern in the string.
The RPAD function adds characters to the end of a character string. It returns a string padded to the right (hence the "R" in "RPAD") to a specified length, and with an optional pad string. The specification of the RPAD function is:
FUNCTION RPAD
(string1 IN VARCHAR2,
padded_length IN NUMBER
[, pad_string IN VARCHAR2])
RETURN VARCHAR2RPAD returns string1 padded on the right to length padded_length with the optional character string pad_string. If you do not specify pad_string, then string1 is padded on the right with spaces. You must specify the padded_length. If string1 already has a length equal to padded_length, then RPAD returns string1 without any additional characters. If padded_length is smaller than the length of string1, RPAD effectively truncates string1: it returns only the first padded_length characters of the incoming string1.
Let's look at some examples of RPAD:
Display the number padded right with zeros to a length of 10:
RPAD ('55', 10, '0') ==> '5500000000'I could also use TO_CHAR to convert from a number to a character (I don't know off-hand why you would do this, but it's good to be reminded that there are usually at least two or three ways to solve any problem):
TO_CHAR (55 * 10000000) ==> '5500000000'
Display the number padded right with zeros to a length of 5:
RPAD ('12345678', 5) ==> '12345'RPAD interprets its padded_length as the maximum length of the string that it may return. As a result, it counts padded_length number of characters from the left (start of the string) and then simply returns that substring of the incoming value. This is the same behavior as that found with LPAD, described earlier in this chapter. Remember: RPAD does not return the rightmost five characters (in the above case "45678").
Place the phrase "sell!" after the names of selected stocks, up to a string length of 45:
RPAD ('HITOP TIES', 45, 'sell!')
==>
' HITOP TIESsell!sell!sell!sell!sell!sell!sell!'Since the length of "HITOP TIES" is 10 and the length of "sell!" is 5, there is room for seven repetitions of the pad string. RPAD does, in fact, generate a repetition of the pattern specified in the pad string.
Place the phrase "sell!" after the names of selected stocks, up to a string length of 43:
RPAD ('HITOP TIES', 43, 'sell!')
==>
'HITOP TIESsell!sell!sell!sell!sell!sell!sel'Because the length of "HITOP TIES" is 10 and the length of "sell!" is 5, there is no longer room for seven full repetitions of the pad string. As a result, the seventh repetition of "sell!" lost its last two characters.
Create a string of 60 dashes to use as a border in a report:
RPAD ('-', 60, '-')
==>
'------------------------------------------------------------'You can use RPAD (and LPAD as well) to generate repetitive sequences of characters. I have used this technique in SQL*Reportwriter V1.1, where graphical objects like boxes are not really available. I can include the RPAD in a SELECT statement in the report, and then use the corresponding field in Text elements to provide lines to break up the data in a report.
The RTRIM function is the opposite of RPAD, and the companion function to LTRIM. Where RPAD adds characters to the right of a string, RTRIM removes, or trims, characters from the end portion of the string. Just as with RPAD, RTRIM offers much more flexibility than simply removing trailing blanks. The specification of the RTRIM function is:
FUNCTION RTRIM (string1 IN VARCHAR2 [, trim_string IN VARCHAR2]) RETURN VARCHAR2
RTRIM returns string1 with all trailing characters removed up to the first character not found in the trim_string. The second parameter is optional and defaults to a single space.
Here are some examples of RTRIM:
Trim all trailing blanks from a string:
RTRIM (`Way Out in Right Field ') ==> 'Way Out in Right Field'
Since I did not specify a trim string, it defaults to a single space and so all trailing spaces are removed.
Trim all the characters in "BAM! ARGH!" from the end of a string:
my_string := 'Sound effects: BAM!ARGH!BAM!HAM'; RTRIM (my_string, 'BAM! ARGH!') ==> 'Sound effects:'
This use of RTRIM stripped off all the letters at the end of the string which are found in "BAM!ARGH!." This includes "BAM" and "HAM," so those words too are removed from the string even though "HAM" is not listed explicitly as a "word" in the trim string. Also, the inclusion of two exclamation marks in the trim string is unnecessary, because RTRIM is not looking for the word "ARGH!", but each of the letters in "ARGH!".
The SOUNDEX function allows you to perform string comparisons based on phonetics (the way a word sounds), as opposed to semantics (the way a word is spelled).[1] SOUNDEX returns a character string which is the "phonetic representation" of the argument. The specification of the SOUNDEX function is as follows:
[1] Oracle Corporation used the algorithm in The Art of Computer Programming, Volume 3, by Donald Knuth, to generate the phonetic representation.
FUNCTION SOUNDEX (string1 IN VARCHAR2) RETURN VARCHAR2
Here are some of the values SOUNDEX generated and how they vary according to the input string:
SOUNDEX ('smith') ==> 'S530'
SOUNDEX ('SMYTHE') ==> ''S530'
SOUNDEX ('smith smith') ==> 'S532'
SOUNDEX ('smith z') ==> 'S532'
SOUNDEX ('feuerstein') ==> 'F623'
SOUNDEX ('feuerst') ==> 'F623'Keep the following SOUNDEX rules in mind when using this function:
The SOUNDEX value always begins with the first letter in the input string.
SOUNDEX only uses the first five consonants in the string to generate the return value.
Only consonants are used to compute the numeric portion of the SOUNDEX value. Except for a possible leading vowel, all vowels are ignored.
SOUNDEX is not case-sensitive. Upper- and lowercase letters return the same SOUNDEX value.
The SOUNDEX function is useful for ad hoc queries, and any other kinds of searches where the exact spelling of a database value is not known or easily determined.
The SUBSTR function is one of the most useful and commonly used character functions. It allows you to extract a portion or subset of contiguous (connected) characters from a string. The substring is specified by starting position and a length.
The specification for the SUBSTR function is:
FUNCTION SUBSTR
(string_in IN VARCHAR2,
start_position_in IN NUMBER
[, substr_length_in IN NUMBER])
RETURN VARCHAR2where the arguments are used as follows:
The source string
The starting position of the substring in string_in
The length of the substring desired (the number of characters to be returned in the substring)
The last parameter, substr_length_in, is optional. If you do not specify a substring length, then SUBSTR returns all the characters to the end of string_in (from the starting position specified).
The start position cannot be zero. If the start position is less than zero, then the substring is retrieved from the back of the string. SUBSTR counts backwards substr_length_in number of characters from the end of string_in. In this case, however, the characters which are extracted are still to the right of the starting position. See Figure 11.2 for an illustration of how the different arguments are used by SUBSTR.
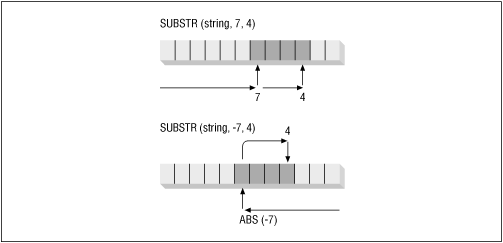
The substr_length_in argument must be greater than zero.
You will find that in practice SUBSTR is very forgiving. Even if you violate the rules for the values of the starting position and the number of characters to be substringed, SUBSTR will not generate errors. Instead, for the most part, it will return NULL -- or the entire string -- as its answer.
Here are some examples of SUBSTR:
If the absolute value of the starting position exceeds the length of the input string, return NULL:
SUBSTR ('now_or_never', 200) ==> NULL
SUBSTR ('now_or_never', -200) ==> NULLIf starting position is 0, SUBSTR acts as though the starting position was actually 1:
SUBSTR ('now_or_never', 0, 3) ==> 'now'
SUBSTR ('now_or_never', 0) ==> 'now_or_never'If the substring length is less than or equal to zero, return NULL:
SUBSTR ('now_or_never', 5, -2) ==> NULL
SUBSTR ('now_or_never', 1, 0) ==> NULLReturn the last character in a string:
SUBSTR ('Another sample string', -1) ==> 'g'This is the cleanest way to get the single last character. A more direct, but cumbersome, approach is this:
SUBSTR
('Sample string', LENGTH ('Sample string'), 1) ==> 'g'In other words, calculate the LENGTH of the string and the one character from the string that starts at that last position. Yuch.
Remove an element from a string list. This is, in a way, the opposite of SUBSTR: I want to extract a portion or substring of a string -- and leave the rest of it intact. Oddly enough, however, I will use SUBSTR to perform this task. Suppose my screen maintains a list of selected temperatures, as follows:
|HOT|COLD|LUKEWARM|SCALDING|
The vertical bar delimits the different items on the list. When the user deselects "LUKEWARM," I now have to remove it from the list, which becomes:
|HOT|COLD|SCALDING|
The best way to accomplish this task is to determine the starting and ending positions of the item to be removed, and then use SUBSTR to take apart the list and put it back together -- without the specified item. Let's walk through this process a step at a time. The list used in the above example contains 29 characters:
String: |HOT|COLD|LUKEWARM|SCALDING| Character index: 1234567890123456789012345679
As you can see, the item "LUKEWARM" starts on position 11 and ends on position 18. To extract this item from the list, I need to pull off the portion of the string before "LUKEWARM" as follows:
SUBSTR ('|HOT|COLD|LUKEWARM|SCALDING|', 1, 10)and then I need to extract the trailing portion of the list (after "LUKEWARM"). Notice that I do not want to keep both of the delimiters when I put these pieces back together, so this next SUBSTR does not include the vertical bar at position 19:
SUBSTR ('|HOT|COLD|LUKEWARM|SCALDING|', 20)Finally, then, to extract "LUKEWARM" from the list, I use the following concatenation of calls to SUBSTR:
SUBSTR ('|HOT|COLD|LUKEWARM|SCALDING|', 1, 10)
||
SUBSTR ('|HOT|COLD|LUKEWARM|SCALDING|', 20)
==>
'|HOT|COLD|SCALDING|'Remove the middle word in a three-word string (in which each word is separated by an underscore) and switch the order of the first and last words. For example, change better_than_ever to ever_better. This is a bit different from the list_remove function because I do not have immediately available to me the length of the element I need to remove. Instead, I have to make use of INSTR twice to calculate that length. Here is the solution expressed as a function:
/* Filename on companion disk: bitesw.sf */
FUNCTION bite_and_switch (tripart_string_in IN VARCHAR2)
RETURN VARCHAR2
IS
/* Location of first underscore */
first_delim_loc NUMBER := INSTR (tripart_string_in, '_', 1, 1);
/* Location of second underscore */
second_delim_loc NUMBER := INSTR (tripart_string_in, '_', 1, 2);
/* Return value of function, set by default to incoming string. */
return_value VARCHAR2(1000) := tripart_string_in;
BEGIN
/* Only switch words if two delimiters are found. */
IF second_delim_loc > 0
THEN
/* Pull out first and second words and stick them together. */
return_value :=
SUBSTR (tripart_string_in, 1, first_delim_loc - 1) || '_' ||
SUBSTR (tripart_string_in, second_delim_loc + 1);
END IF;
/* Return the switched string */
RETURN return_value;
END bite_and_switch;Use SUBSTR to extract the portion of a string between the specified starting and ending points. I run into this requirement all the time. SUBSTR requires a starting position and the number of characters to pull out. Often, however, I have only the starting position and the ending position -- and I then have to compute the number of characters in between. Is it just the difference between the end and start positions? Is it one more or one less than that? Invariably, I get it wrong the first time and have to scribble a little example on scrap paper to prove the formula to myself.
So to save all of you the trouble, I offer a tiny function below, called "betwnstr" (for: "BETWeeN STRing"). This function encapsulates the calculation you must perform to come up with the number of characters between start and end positions, which is:
end_position - start_position + 1 /* Filename on companion disk: betwnstr.sf */ FUNCTION betwnstr (string_in IN VARCHAR2, start_in IN INTEGER, end_in IN INTEGER) RETURN VARCHAR2 IS BEGIN RETURN SUBSTR (string_in, start_in, end_in - start_in + 1); END;
While this function does not provide the full flexibility offered by SUBSTR (for example, with negative starting positions), it offers a starting point for the kind of encapsulation you should be performing in these situations.
By the way, SUBSTRB is the multiple-byte character set version of SUBSTR. For single-byte character sets (such as American English), SUBSTRB returns the same values as SUBSTR.
The TRANSLATE function is a variation on REPLACE. REPLACE replaces every instance of a set of characters with another set of characters; that is, REPLACE works with entire words or patterns. TRANSLATE replaces single characters at a time, translating the nth character in the match set with the nth character in the replacement set. The specification of the TRANSLATE is as follows:
FUNCTION TRANSLATE
(string_in IN VARCHAR2,
search_set IN VARCHAR2,
replace_set VARCHAR2)
RETURN VARCHAR2where string_in is the string in which characters are to be translated, search_set is the set of characters to be translated (if found), and replace_set is the set of characters which will be placed in the string. Unlike REPLACE, where the last argument could be left off, you must include all three arguments when you use TRANSLATE. Any of the three arguments may, however, be NULL, in which case TRANSLATE always returns NULL.
Here are some examples of the effect of TRANSLATE:
TRANSLATE ('abcd', 'ab', '12') ==> '12cd'
TRANSLATE ('12345', '15', 'xx') ==> 'x234x'
TRANSLATE ('grumpy old possum', 'uot', '%$*') ==> 'gr%mpy $ld p$ss%m'
TRANSLATE ('my language needs the letter e', 'egms', 'X')
==>
'y lanuaX nXXd thX lXttXr X';
TRANSLATE ('please go away', 'a', NULL) ==> NULLYou can deduce a number of the usage rules for TRANSLATE from the above examples, but I spell them out here:
If the search set contains a character not found in the string, then no translation is performed for that character.
If the string contains a character not found in the search set, then that character is not translated.
If the search set contains more characters than the replace set, then all the "trailing" search characters that have no match in the replace set are removed from the string. In the following example, a, b, and c are changed to z, y, and x, respectively. But the letter "d" is removed from the return string entirely since it had no corresponding character in the replace set.
TRANSLATE ('abcdefg', 'abcd', 'zyx') ==> 'zyxefg'In these cases, NULL is the matching "character" for all extra characters in the search set. When you replace a character with NULL it is the same as removing that character from the string.
If any of the three arguments is NULL, then the result of the translation is NULL. This is consistent with a basic tenet of NULLs: apply an operation to an unknown value and you always get an unknown value.
The TRANSLATE function comes in handy when you need to change a whole set of characters in a string, regardless of the order in which they appear in the string. Section 11.2.5, "Verifying String Formats with TRANSLATE" demonstrates how handy this feature can be.
The UPPER function converts all letters in the specified string to uppercase. The specifications of the UPPER function are:
FUNCTION UPPER (string1 IN CHAR) RETURN CHAR FUNCTION UPPER (string1 IN VARCHAR2) RETURN VARCHAR2
As I noted at the beginning of this chapter, UPPER and LOWER will actually return a fixed-length string if the incoming string is fixed length. UPPER will not change any characters in the string which are not letters, since case is irrelevant for numbers and special characters such as $.
Here are some examples of the effect of UPPER:
UPPER ('short little letters no more') ==> 'SHORT LITTLE LETTERS NO MORE'
UPPER ('123abc') ==> '123ABC'UPPER and its partner in case conversion, LOWER, are useful for guaranteeing a consistent case when comparing strings. PL/SQL is not a case-sensitive language as concerns its own syntax and names of identifiers. It is sensitive to case, however, in character strings, whether found in named constants, literals, or variables. The string "ABC" is not the same as "abc", and this can cause problems in your programs if you are not careful and consistent in your handling of such values.
|  | |
| III. Built-In Functions |  | 11.2 Character Function Examples |
Copyright (c) 2000 O'Reilly & Associates. All rights reserved.